Le clustering (ou partitionnement de données) est une technique d'apprentissage non supervisé qui regroupe automatiquement des données similaires, sans étiquettes fournies à l'avance. L'algorithme découvre lui-même des groupes (clusters) dans les données, là où un humain ne verrait qu'un nuage de points.
Ce guide définit le clustering, montre comment l'appliquer avec k-means et scikit-learn (code testé, pas à pas), explique comment choisir le nombre de clusters avec la méthode du coude et le coefficient de silhouette, puis compare les principaux algorithmes. Il approfondit la famille non supervisée présentée dans les types d'apprentissage.
Ce que vous allez apprendre
Section intitulée « Ce que vous allez apprendre »- Définir le clustering et le situer dans l'apprentissage non supervisé.
- Entraîner un modèle k-means avec scikit-learn.
- Choisir le bon nombre de clusters (coude et silhouette).
- Comparer k-means, DBSCAN et le clustering hiérarchique.
- Reconnaître les cas d'usage concrets du clustering.
Qu'est-ce que le clustering ?
Section intitulée « Qu'est-ce que le clustering ? »Le clustering regroupe des observations qui se ressemblent. Contrairement à la classification, où l'on connaît déjà la catégorie de chaque exemple, le clustering travaille sur des données sans étiquettes : il n'y a pas de bonne réponse fournie, l'algorithme cherche des structures par lui-même.
Le critère de regroupement est la similarité, mesurée par une distance (souvent la distance euclidienne). Deux points proches finissent dans le même cluster, deux points éloignés dans des clusters différents.
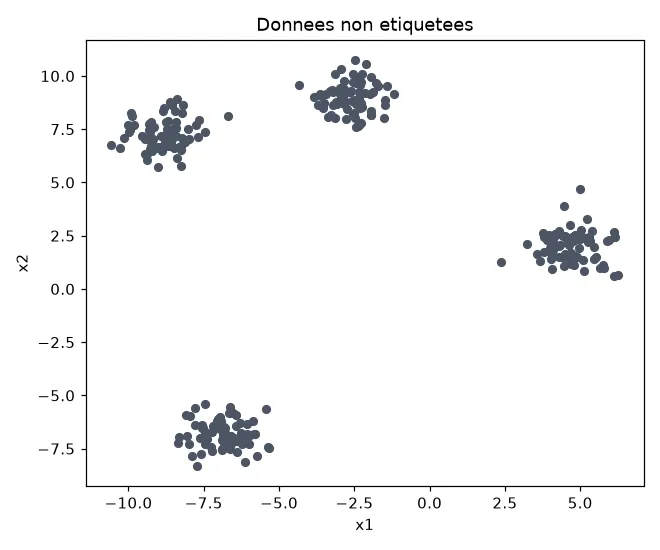
Voici un jeu de données non étiquetées : à l'oeil, on devine des groupes, mais rien ne les nomme.
Entraîner un k-means avec scikit-learn
Section intitulée « Entraîner un k-means avec scikit-learn »k-means est l'algorithme de clustering le plus courant. Il partitionne les données en k groupes en plaçant k centres (centroïdes) et en assignant chaque point au centre le plus proche, de façon itérative jusqu'à stabilisation.
Installez d'abord les bibliothèques, avec des versions épinglées pour la reproductibilité :
pip install scikit-learn==1.9.0 numpy==2.5.1 matplotlib==3.11.0Le code tient en quelques lignes. On génère des données de démonstration avec
make_blobs, puis on entraîne un k-means à 4 clusters :
from sklearn.datasets import make_blobsfrom sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_score
# Données de démonstration : 300 points, 4 groupesX, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.70, random_state=42)
# Entraînement de k-meanskm = KMeans(n_clusters=4, random_state=42, n_init=10)labels = km.fit_predict(X)
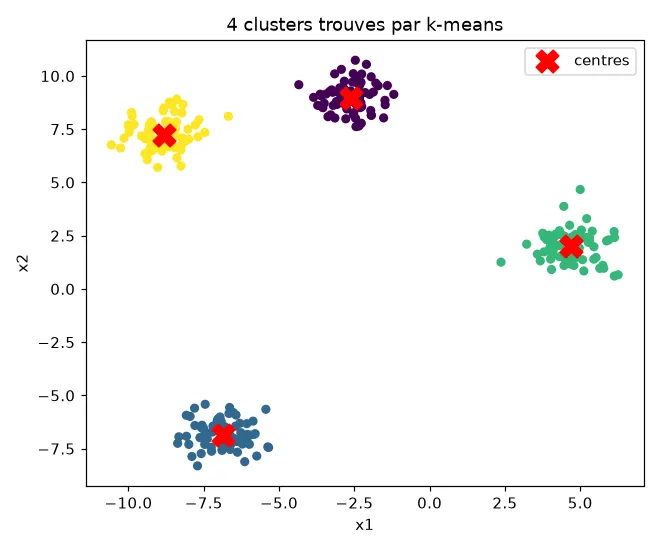
print("Inertie :", round(km.inertia_, 1))print("Silhouette :", round(silhouette_score(X, labels), 3))La sortie confirme un bon partitionnement :
Inertie : 277.5Silhouette : 0.855L'attribut labels contient le numéro de cluster de chaque point, et
km.cluster_centers_ les coordonnées des centres. En colorant les points par
cluster et en marquant les centres, le résultat est net :
Choisir le bon nombre de clusters
Section intitulée « Choisir le bon nombre de clusters »Le principal défi de k-means : il faut lui donner k, le nombre de clusters, alors que c'est souvent ce qu'on cherche. Deux méthodes complémentaires aident à le trouver.
La méthode du coude
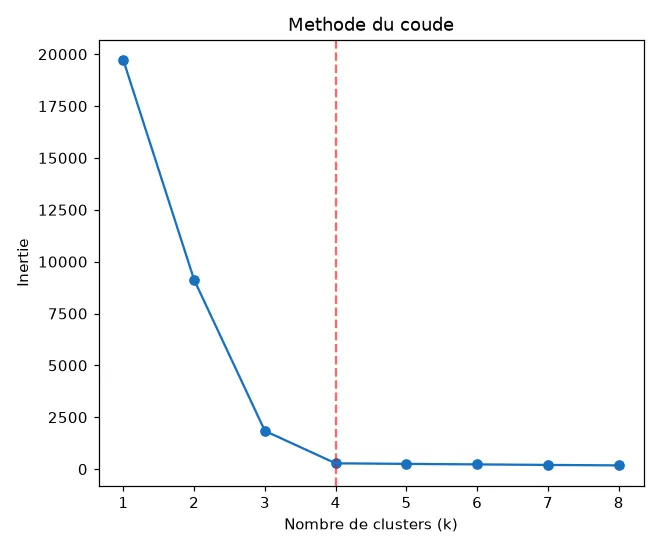
Section intitulée « La méthode du coude »On entraîne k-means pour plusieurs valeurs de k et on trace l'inertie (la somme des distances des points à leur centre). L'inertie baisse toujours quand k augmente, mais elle chute brutalement puis se stabilise : le « coude » de la courbe indique le bon k.
for k in range(1, 9): m = KMeans(n_clusters=k, random_state=42, n_init=10).fit(X) print(k, round(m.inertia_, 1))1 19710.62 9125.83 1840.94 277.55 251.06 225.6L'inertie s'effondre jusqu'à k=4 (de 1840 à 277), puis ne baisse presque plus. Le coude est donc à 4 clusters, ce que la courbe montre clairement :
Le coefficient de silhouette
Section intitulée « Le coefficient de silhouette »Le coefficient de silhouette mesure à quel point chaque point est bien dans son cluster (proche des siens, loin des autres). Il varie de -1 à 1 ; plus haut est meilleur. On le calcule pour plusieurs k et on garde le maximum :
for k in range(2, 9): m = KMeans(n_clusters=k, random_state=42, n_init=10).fit(X) print(k, round(silhouette_score(X, m.labels_), 3))2 0.6093 0.7894 0.8555 0.739Le score est maximal à k=4 (0.855), ce qui confirme la méthode du coude. Quand les deux méthodes concordent, le choix est solide.
Les principaux algorithmes de clustering
Section intitulée « Les principaux algorithmes de clustering »k-means n'est pas seul. Le bon algorithme dépend de la forme des groupes et de la présence de bruit dans les données.
| Algorithme | Principe | Forces | Limites |
|---|---|---|---|
| k-means | k centres, distance minimale | Rapide, simple | Il faut donner k ; clusters sphériques |
| DBSCAN | Densité de points | Trouve k seul, gère le bruit, formes libres | Sensible à ses deux paramètres |
| Clustering hiérarchique | Fusions successives (dendrogramme) | Pas besoin de k a priori, visuel | Lent sur gros volumes |
En pratique : k-means pour démarrer et pour des groupes bien séparés, DBSCAN quand les clusters ont des formes irrégulières ou qu'il y a des points aberrants, le hiérarchique pour explorer visuellement la structure.
Cas d'usage du clustering
Section intitulée « Cas d'usage du clustering »Le clustering sert partout où l'on veut révéler des groupes sans les connaître à l'avance :
- Segmentation client : regrouper les clients par comportement d'achat pour cibler le marketing.
- Détection d'anomalies : les points qui n'entrent dans aucun cluster dense sont des candidats suspects (fraude, panne).
- Compression et résumé : remplacer des milliers de points par quelques centres représentatifs.
- Organisation de contenu : regrouper des documents ou des images similaires.
FAQ : questions fréquentes
Section intitulée « FAQ : questions fréquentes »À retenir
Section intitulée « À retenir »- Le clustering regroupe des données similaires sans étiquettes : c'est de l'apprentissage non supervisé.
- k-means est l'algorithme de référence : simple, rapide, mais il faut lui donner k.
- La méthode du coude et la silhouette aident à choisir le nombre de clusters ; les faire concorder fiabilise le choix.
- DBSCAN gère le bruit et les formes libres, le hiérarchique offre une vue visuelle.
- Cas d'usage phares : segmentation client et détection d'anomalies.