PyTorch est le framework de deep learning le plus utilisé : il permet de définir un réseau de neurones, de l'entraîner sur CPU ou GPU, et de lui faire apprendre des motifs complexes en quelques lignes. Ce guide construit un réseau de neurones qui apprend une frontière non linéaire, l'entraîne, puis visualise ce qu'il a appris.
Vous verrez comment définir un réseau avec torch.nn, la boucle
d'entraînement (forward, perte, rétropropagation, optimiseur), l'exécution sur
GPU, et pourquoi un réseau de neurones réussit là où un modèle linéaire
échoue. Ce guide prolonge le concept de deep learning.
Public : intermédiaire à avancé, à l'aise avec Python.
Ce que vous allez apprendre
Section intitulée « Ce que vous allez apprendre »- Installer PyTorch (CPU ou GPU).
- Définir un réseau de neurones avec
torch.nn. - Écrire une boucle d'entraînement complète.
- Exécuter le calcul sur GPU avec
.to(device). - Visualiser la frontière de décision apprise.
Qu'est-ce que PyTorch ?
Section intitulée « Qu'est-ce que PyTorch ? »PyTorch est une bibliothèque Python qui manipule des tenseurs (des tableaux multidimensionnels) avec accélération GPU et différentiation automatique. Ces deux briques sont le coeur du deep learning : les tenseurs portent les données et les poids, l'autograd calcule automatiquement les gradients nécessaires à la rétropropagation.
Concrètement, vous décrivez le réseau et la perte à minimiser, et PyTorch se charge de calculer comment ajuster chaque poids. C'est ce qui rend possible l'entraînement de réseaux à des millions de paramètres.
Installer PyTorch
Section intitulée « Installer PyTorch »Travaillez toujours dans un environnement virtuel isolé, jamais dans le Python système. Pour une machine sans carte graphique, la version CPU suffit pour ce guide :
python3 -m venv venv && source venv/bin/activatepip install torch==2.7.1 numpy==2.2.6 matplotlib==3.10.9Sur une machine équipée d'un GPU NVIDIA, installez la variante CUDA pour profiter de l'accélération :
pip install torch==2.7.1 --index-url https://download.pytorch.org/whl/cu126Vérifiez que PyTorch voit le GPU :
import torchprint(torch.cuda.is_available()) # True si un GPU est disponiblePréparer des données non linéaires
Section intitulée « Préparer des données non linéaires »Pour montrer l'intérêt d'un réseau de neurones, on utilise un jeu de données que la régression linéaire ne peut pas séparer : deux lunes entrelacées. On les génère avec NumPy, puis on les convertit en tenseurs placés sur le bon device (GPU si disponible) :
import torch, time, numpy as npfrom torch import nn
torch.manual_seed(42); np.random.seed(42)device = "cuda" if torch.cuda.is_available() else "cpu"
def make_moons(n=1000, noise=0.15): n2 = n // 2; t = np.linspace(0, np.pi, n2) x1 = np.stack([np.cos(t), np.sin(t)], 1) x2 = np.stack([1 - np.cos(t), 1 - np.sin(t) - 0.5], 1) X = np.vstack([x1, x2]); y = np.array([0] * n2 + [1] * n2) X += noise * np.random.randn(*X.shape) return X.astype("float32"), y.astype("int64")
X, y = make_moons(1000)idx = np.random.permutation(len(X)); tr, te = idx[:800], idx[800:]Xtr = torch.tensor(X[tr]).to(device); ytr = torch.tensor(y[tr]).to(device)Xte = torch.tensor(X[te]).to(device); yte = torch.tensor(y[te]).to(device)Définir le réseau de neurones
Section intitulée « Définir le réseau de neurones »Un réseau se décrit comme un empilement de couches. Ici, deux couches cachées de 16 neurones avec une activation ReLU, et une sortie à deux classes :
model = nn.Sequential( nn.Linear(2, 16), nn.ReLU(), nn.Linear(16, 16), nn.ReLU(), nn.Linear(16, 2),).to(device)
opt = torch.optim.Adam(model.parameters(), lr=0.01)loss_fn = nn.CrossEntropyLoss()nn.Linear est une couche entièrement connectée, nn.ReLU la fonction
d'activation, Adam l'optimiseur qui ajuste les poids, et
CrossEntropyLoss la perte adaptée à la classification.
La boucle d'entraînement
Section intitulée « La boucle d'entraînement »Chaque itération (epoch) répète le même cycle : prédire, mesurer l'erreur, rétropropager, mettre à jour les poids :
t0 = time.time()for epoch in range(200): model.train() opt.zero_grad() # réinitialiser les gradients loss = loss_fn(model(Xtr), ytr) # forward + perte loss.backward() # rétropropagation opt.step() # mise à jour des poids if (epoch + 1) % 50 == 0: model.eval() with torch.no_grad(): acc = (model(Xte).argmax(1) == yte).float().mean().item() print(f"Epoch {epoch+1} | loss {loss.item():.3f} | accuracy test {acc:.3f}")print(f"Entraînement en {time.time()-t0:.2f}s sur {device}")Sur un GPU NVIDIA H100, l'entraînement complet donne :
Epoch 50 | loss 0.213 | accuracy test 0.900Epoch 100 | loss 0.045 | accuracy test 0.990Epoch 150 | loss 0.023 | accuracy test 0.985Epoch 200 | loss 0.018 | accuracy test 0.985Entraînement en 1.50s sur cudaLe réseau atteint 98,5 % de bonnes réponses sur les données de test, en moins de deux secondes.
Visualiser ce que le réseau a appris
Section intitulée « Visualiser ce que le réseau a appris »En colorant chaque zone du plan selon la classe prédite, on voit la frontière de décision que le réseau a construite. Elle épouse la forme courbe des deux lunes, ce qu'une droite ne pourrait jamais faire :
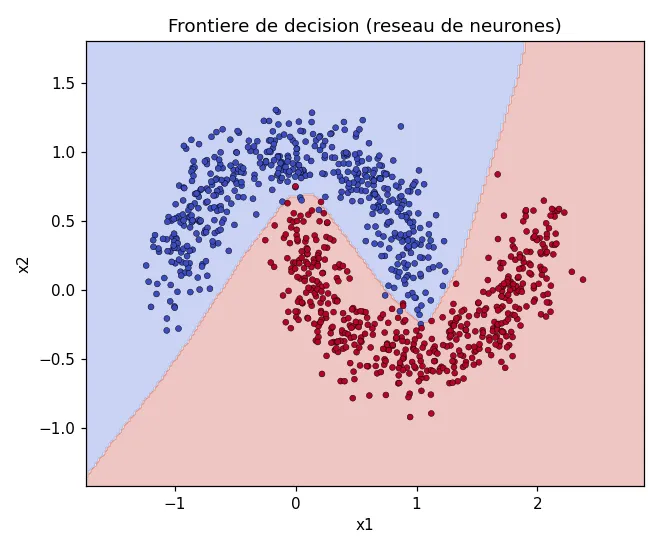
C'est toute la puissance d'un réseau de neurones : grâce à ses couches et à ses fonctions d'activation non linéaires, il modélise des relations que les modèles linéaires ne capturent pas.
FAQ : questions fréquentes
Section intitulée « FAQ : questions fréquentes ».to(device).loss.backward() calcule automatiquement les gradients de la perte par rapport à chaque poids, et opt.step() ajuste les poids pour réduire l'erreur. C'est le coeur de l'apprentissage.À retenir
Section intitulée « À retenir »- PyTorch manipule des tenseurs avec GPU et différentiation automatique.
- Un réseau se décrit comme un empilement de couches avec
torch.nn. - La boucle d'entraînement répète : forward, perte,
backward,step. .to(device)rend le code portable entre CPU et GPU sans le changer.- Les couches non linéaires permettent d'apprendre des frontières courbes, hors de portée d'un modèle linéaire.