La régression linéaire est une méthode de machine learning supervisé qui prédit une valeur numérique en modélisant la relation entre variables par une droite. Elle répond à des questions du type « quel prix pour cette surface ? » ou « quelles ventes pour ce budget publicitaire ? », en traçant la droite qui colle au mieux aux données observées.
Ce guide définit la régression linéaire, explique la droite des moindres carrés, la met en oeuvre avec scikit-learn (code testé), montre comment l'évaluer avec le coefficient de détermination R², et distingue régression simple et multiple. Il approfondit la classification et la régression supervisées.
Ce que vous allez apprendre
Section intitulée « Ce que vous allez apprendre »- Définir la régression linéaire et son principe.
- Comprendre la droite des moindres carrés.
- Entraîner un modèle avec scikit-learn et prédire une valeur.
- Évaluer un modèle avec R² et le RMSE.
- Distinguer régression simple et régression multiple.
Qu'est-ce que la régression linéaire ?
Section intitulée « Qu'est-ce que la régression linéaire ? »La régression linéaire cherche la droite qui résume le mieux la relation entre une variable à prédire et une ou plusieurs variables explicatives. Avec une seule variable explicative, cette droite s'écrit :
y = a * x + boù a est la pente (de combien y augmente quand x augmente de 1) et b l'ordonnée à l'origine (la valeur de y quand x vaut 0). Le modèle apprend les valeurs de a et b qui minimisent l'erreur sur les données connues.
C'est de l'apprentissage supervisé : on fournit des exemples où la réponse est connue, et le modèle prédit ensuite la valeur pour de nouvelles entrées. Contrairement à la classification, la sortie est une valeur continue, pas une catégorie.
La droite des moindres carrés
Section intitulée « La droite des moindres carrés »Comment trouver la « meilleure » droite ? En minimisant la somme des carrés des écarts entre les points réels et la droite : c'est la méthode des moindres carrés. Élever au carré évite que les écarts positifs et négatifs s'annulent, et pénalise fortement les grosses erreurs.
Entraîner une régression linéaire avec scikit-learn
Section intitulée « Entraîner une régression linéaire avec scikit-learn »Installez les bibliothèques avec des versions épinglées :
pip install scikit-learn==1.9.0 numpy==2.5.1 matplotlib==3.11.0On génère des données de démonstration, on sépare en jeu d'entraînement et de test, puis on entraîne le modèle :
from sklearn.datasets import make_regressionfrom sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import r2_score, mean_squared_error
# Données : 100 points avec du bruitX, y = make_regression(n_samples=100, n_features=1, noise=15, random_state=42)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Entraînementmodel = LinearRegression().fit(X_train, y_train)y_pred = model.predict(X_test)
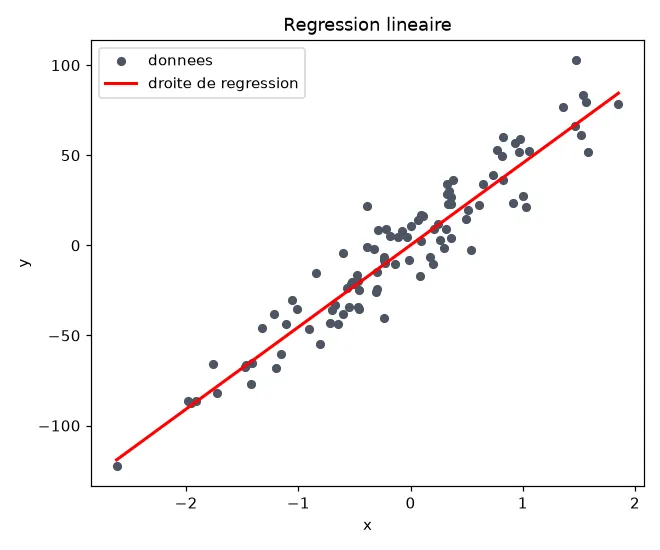
print("Pente :", round(float(model.coef_[0]), 2))print("Ordonnée :", round(float(model.intercept_), 2))print("R2 :", round(r2_score(y_test, y_pred), 3))print("RMSE :", round(mean_squared_error(y_test, y_pred) ** 0.5, 2))La sortie donne l'équation apprise et la qualité du modèle :
Pente : 45.5Ordonnée : 0.15R2 : 0.874RMSE : 15.31Le modèle a appris la droite y = 45.5 * x + 0.15. Superposée aux données, elle
suit bien la tendance :
Évaluer un modèle de régression
Section intitulée « Évaluer un modèle de régression »Deux indicateurs complémentaires mesurent la qualité d'une régression.
- Le coefficient de détermination R² : la part de la variation expliquée par le modèle, entre 0 et 1. Un R² de 0.874 signifie que le modèle explique 87 % de la variabilité des données. Plus il est proche de 1, mieux c'est.
- Le RMSE (racine de l'erreur quadratique moyenne) : l'erreur moyenne de prédiction, dans l'unité de la variable cible. Un RMSE de 15.31 signifie que les prédictions se trompent en moyenne d'environ 15 unités.
Le R² dit quelle proportion est expliquée, le RMSE dit de combien on se trompe. On les regarde ensemble.
Régression simple ou multiple
Section intitulée « Régression simple ou multiple »La régression linéaire simple utilise une seule variable explicative (une droite). La régression multiple en utilise plusieurs : le modèle apprend alors un plan ou un hyperplan, avec un coefficient par variable.
Simple : y = a * x + bMultiple : y = a1 * x1 + a2 * x2 + ... + bLe code scikit-learn est identique : il suffit de fournir un X à plusieurs
colonnes. La régression multiple est la plus fréquente en pratique, car un
phénomène dépend rarement d'un seul facteur.
Cas d'usage de la régression linéaire
Section intitulée « Cas d'usage de la régression linéaire »La régression linéaire sert dès qu'on veut prédire une quantité à partir de facteurs mesurables :
- Estimation de prix : immobilier, véhicules d'occasion, selon leurs caractéristiques.
- Prévision de ventes en fonction du budget marketing ou de la saison.
- Analyse d'impact : mesurer l'effet d'une variable sur une autre.
- Base de référence : c'est le modèle le plus simple, celui auquel on compare des modèles plus complexes.
FAQ : questions fréquentes
Section intitulée « FAQ : questions fréquentes »À retenir
Section intitulée « À retenir »- La régression linéaire prédit une valeur continue avec une droite
y = a*x + b. - La méthode des moindres carrés trouve la droite qui minimise les carrés des écarts.
- scikit-learn l'entraîne en quelques lignes avec
LinearRegression. - On évalue avec R² (part expliquée) et RMSE (erreur moyenne).
- La régression multiple généralise à plusieurs variables, avec le même code.