![]()
dkron est un ordonnanceur cron distribué et tolérant aux pannes, écrit en Go. Là où un crontab vit sur une seule machine, dkron répartit vos tâches planifiées sur un cluster sans point de défaillance unique, avec une interface web, une API REST et un historique des exécutions. Ce guide monte un cluster haute disponibilité en Docker Compose, crée des jobs, et prouve la tolérance aux pannes en tuant le leader pour observer la ré-élection. Testé avec dkron 4.1.1. Pour intermédiaires à l'aise avec Docker et les API.
Ce que vous allez apprendre
Section intitulée « Ce que vous allez apprendre »- Ce qu'apporte un cron distribué par rapport à
cron. - L'architecture de dkron (Serf, Raft, executors).
- Monter un cluster HA de trois serveurs en Docker Compose.
- Créer un job planifié via l'API et l'interface.
- Vérifier la tolérance aux pannes par un failover réel.
Qu'est-ce que dkron
Section intitulée « Qu'est-ce que dkron »dkron est un service de planification qui exécute des commandes à intervalle régulier, comme cron, mais à l'échelle d'un parc de machines. Sa promesse tient en trois mots : distribué, tolérant aux pannes, sans SPOF (Single Point Of Failure). Concrètement, plusieurs nœuds forment un cluster ; si celui qui pilote tombe, un autre prend le relais automatiquement, sans intervention humaine.
On le pilote de trois façons : une interface web pour créer et suivre les jobs, une API REST pour l'automatisation, et des executors qui réalisent le travail (shell, HTTP, et d'autres via plugins). Le projet est open source, maintenu par la communauté sous dkron-io/dkron.
Pourquoi pas simplement cron
Section intitulée « Pourquoi pas simplement cron »Le cron classique rend d'énormes services, mais il montre vite ses limites en production. Il vit sur une seule machine : si elle tombe, les tâches ne partent plus. Il ne garde aucun historique exploitable, n'offre aucune interface, et ne sait pas cibler plusieurs serveurs ni gérer des dépendances entre tâches.
dkron répond à chacun de ces manques. La planification survit à la panne d'un nœud, chaque exécution est tracée avec sa sortie, l'interface montre l'état du cluster, et on cible les machines par tags. C'est le passage d'un crontab isolé à un ordonnanceur de cluster gouverné.
L'architecture en bref
Section intitulée « L'architecture en bref »dkron s'appuie sur deux briques éprouvées de l'écosystème HashiCorp. Serf gère l'appartenance au cluster et la détection de panne via un protocole gossip : chaque nœud sait en permanence qui est vivant. Raft assure la cohérence et l'élection du leader : à tout instant, un seul nœud planifie, et s'il disparaît, les autres en réélisent un.
Un cluster mélange deux rôles. Les serveurs participent au consensus Raft et peuvent planifier ; les agents se contentent d'exécuter les tâches qu'on leur confie. On sélectionne les cibles d'un job par tags, exactement comme un inventaire.
Monter un cluster HA en Docker Compose
Section intitulée « Monter un cluster HA en Docker Compose »On déploie trois serveurs (pour un quorum Raft qui survit à une panne) et un agent d'exécution. L'image officielle est dkron/dkron, épinglée ici en 4.1.1.
-
Écrire la stack dans un fichier
docker-compose.yml:services:dkron1:image: dkron/dkron:4.1.1@sha256:2c18b09d6069d572a3a38c2a390ec0fa0659814e12149f9c959f5935dbb6af1bcommand: agent --server --bootstrap-expect=3 --node-name=dkron1hostname: dkron1ports:- "8899:8080" # interface web et APIenvironment:- GODEBUG=netdns=godkron2:image: dkron/dkron:4.1.1@sha256:2c18b09d6069d572a3a38c2a390ec0fa0659814e12149f9c959f5935dbb6af1bcommand: agent --server --bootstrap-expect=3 --retry-join=dkron1:8946 --node-name=dkron2hostname: dkron2environment:- GODEBUG=netdns=godepends_on: [dkron1]dkron3:image: dkron/dkron:4.1.1@sha256:2c18b09d6069d572a3a38c2a390ec0fa0659814e12149f9c959f5935dbb6af1bcommand: agent --server --bootstrap-expect=3 --retry-join=dkron1:8946 --node-name=dkron3hostname: dkron3environment:- GODEBUG=netdns=godepends_on: [dkron1]dkron-agent:image: dkron/dkron:4.1.1@sha256:2c18b09d6069d572a3a38c2a390ec0fa0659814e12149f9c959f5935dbb6af1bcommand: agent --retry-join=dkron1:8946 --tag worker=true --node-name=agent1hostname: agent1environment:- GODEBUG=netdns=godepends_on: [dkron1] -
Démarrer le cluster :
Fenêtre de terminal docker compose up -dLe drapeau
--bootstrap-expect=3fait patienter dkron jusqu'à ce que les trois serveurs soient présents avant d'élire un leader. Les nœuds se rejoignent par--retry-joinsur le port Serf (8946).
Après quelques secondes, on vérifie l'état du cluster par l'API :
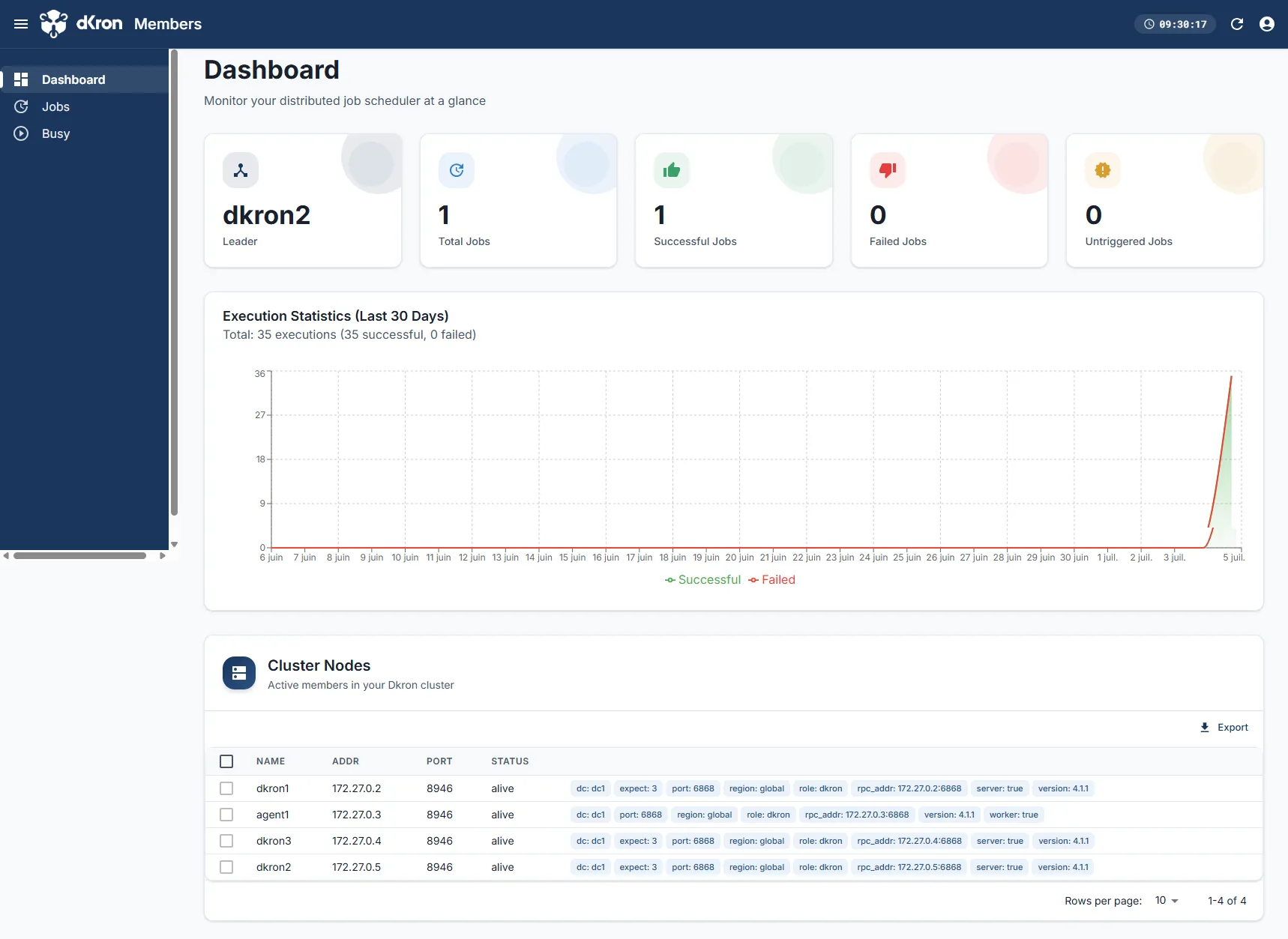
curl -s http://localhost:8899/v1/leader | grep -o '"Name":"[^"]*"'curl -s http://localhost:8899/v1/members | grep -o '"Name":"[^"]*"'"Name":"dkron2" # le leader élu"Name":"dkron1" "Name":"dkron2" "Name":"dkron3" "Name":"agent1"L'interface web répond sur http://localhost:8899. Son tableau de bord affiche le leader, les compteurs de jobs, les statistiques d'exécution et, tout en bas, la liste des membres du cluster avec leur statut.
Créer un job planifié
Section intitulée « Créer un job planifié »Un job décrit une commande, une planification et une cible. On le crée via l'API avec curl. Ici, un job shell qui s'exécute toutes les 15 secondes sur l'agent porteur du tag worker :
curl -s -XPOST http://localhost:8899/v1/jobs -H "Content-Type: application/json" -d '{ "name": "sauvegarde-demo", "schedule": "@every 15s", "timezone": "Europe/Paris", "owner": "stephane", "tags": {"worker": "true:1"}, "concurrency": "forbid", "executor": "shell", "executor_config": { "shell": "true", "command": "echo Sauvegarde OK sur $(hostname) a $(date +%H:%M:%S)" }}'La clé "tags": {"worker": "true:1"} cible un nœud portant worker=true ; la valeur concurrency: "forbid" empêche deux exécutions simultanées du même job. On peut aussi créer un job depuis l'interface, avec le bouton Create :
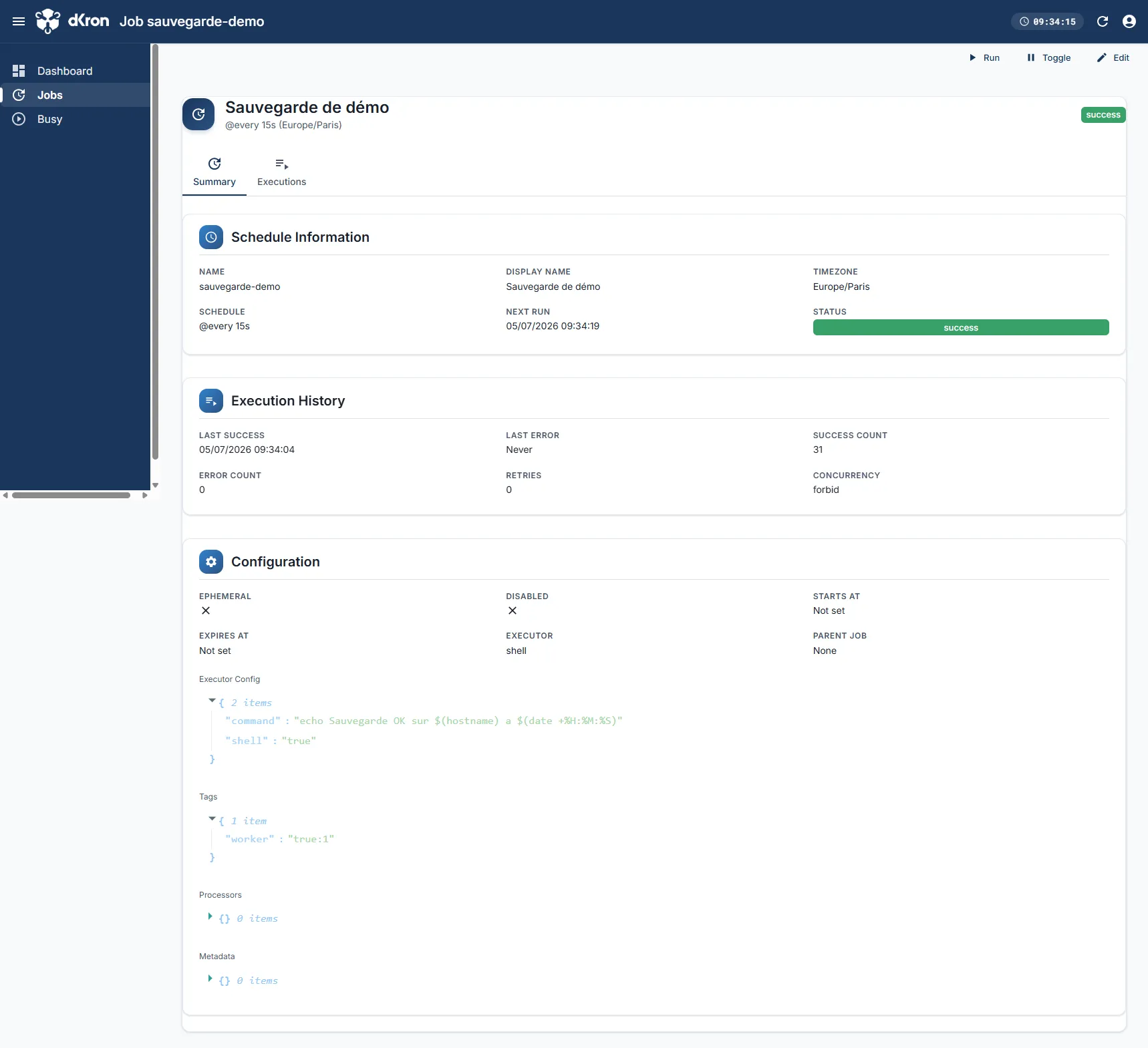
Le détail d'un job récapitule sa planification, son executor, ses tags et ses compteurs de succès :
Suivre les exécutions
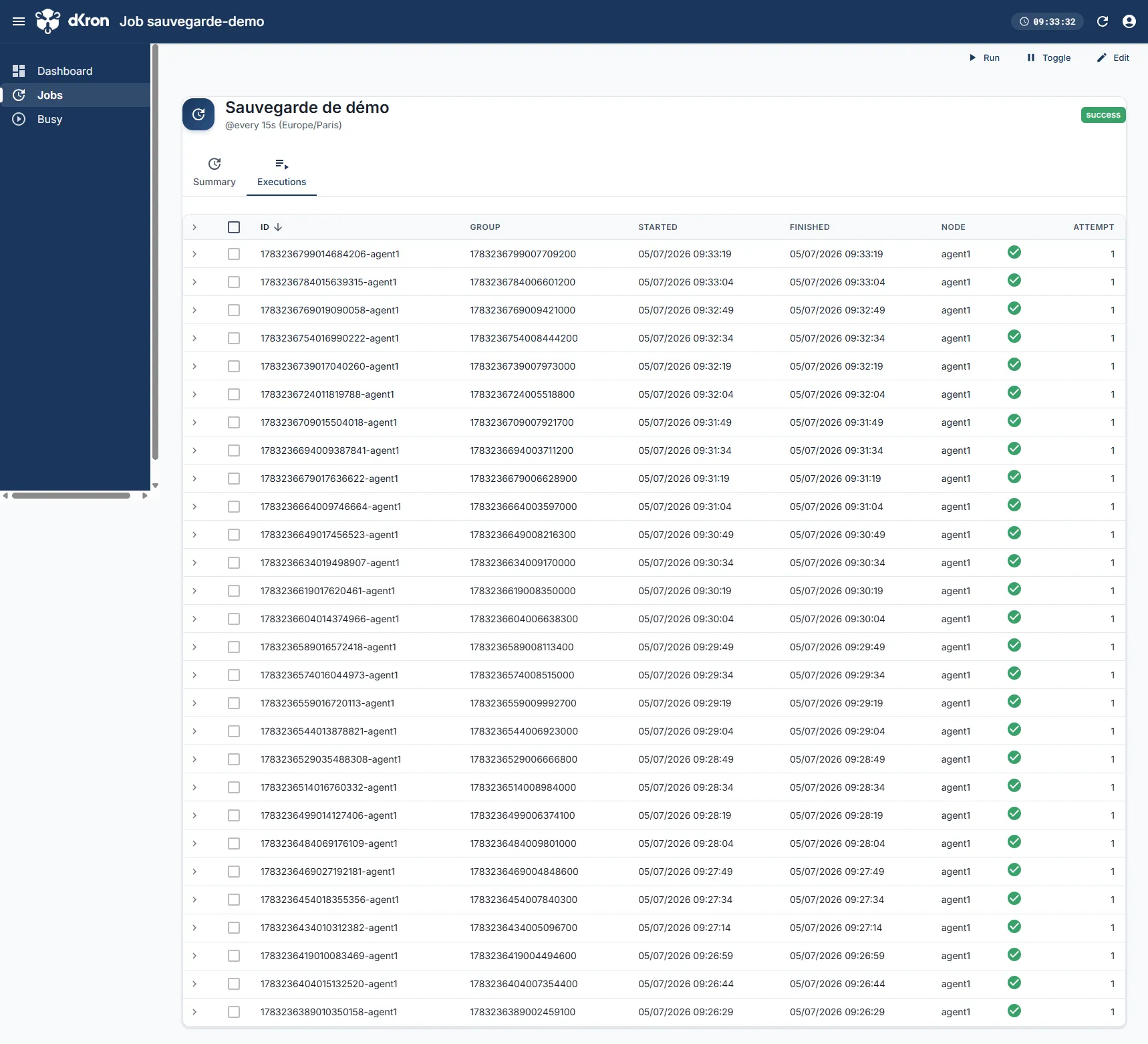
Section intitulée « Suivre les exécutions »Chaque déclenchement produit une exécution tracée. La vue Executions liste l'historique, avec le nœud qui a exécuté, l'horodatage et le statut :
En ouvrant une exécution, on lit sa sortie exacte, ce que cron ne conserve jamais :

La même information est disponible par l'API, utile pour la supervision :
curl -s "http://localhost:8899/v1/jobs/sauvegarde-demo/executions" | tail... "success":true, "output":"Sauvegarde OK sur agent1 a 09:28:04\n", "node_name":"agent1" ...La haute disponibilité à l'épreuve
Section intitulée « La haute disponibilité à l'épreuve »L'argument central de dkron, c'est de survivre à la panne du nœud qui planifie. On le vérifie en tuant le leader et en observant la ré-élection.
# le leader avant la pannecurl -s http://localhost:8899/v1/leader | grep -o '"Name":"[^"]*"' # -> "Name":"dkron2"
# on arrête brutalement le leaderdocker kill lab-dkron-dkron2-1
# quelques secondes plus tard, un nouveau leader a été élucurl -s http://localhost:8899/v1/leader | grep -o '"Name":"[^"]*"' # -> "Name":"dkron3"En moins de dix secondes, Raft a réélu dkron3 comme leader, et le job a continué de s'exécuter sur l'agent sans rien perdre. C'est très exactement le comportement sans SPOF annoncé.
Bonnes pratiques et pièges
Section intitulée « Bonnes pratiques et pièges »Quelques réflexes évitent les mauvaises surprises. Utilisez shell: "true" dès que la commande contient des variables. Ciblez toujours vos jobs par tags plutôt que de laisser tous les nœuds s'exécuter. Posez concurrency: "forbid" sur les tâches longues pour éviter les chevauchements.
Côté production, deux points sont non négociables. Le trafic gossip entre nœuds doit être chiffré (clé d'encryption Serf), et l'API comme l'interface doivent passer derrière du TLS et une authentification. Un cluster dkron ouvert en clair, c'est une exécution de commandes à distance offerte au premier venu.
À retenir
Section intitulée « À retenir »- dkron est un cron distribué tolérant aux pannes : plus de crontab isolé, un cluster sans SPOF.
- Il s'appuie sur Serf (appartenance, gossip) et Raft (cohérence, élection du leader).
- Un cluster mêle serveurs (planifient) et agents (exécutent) ; on cible par tags.
- On crée les jobs par API ou par l'interface, avec historique et sortie conservés.
- La haute disponibilité est réelle : tuer le leader déclenche une ré-élection en quelques secondes.
- En production, chiffrez le gossip et protégez l'API par TLS et authentification.