![]()
L’intelligence artificielle (IA) est un domaine en pleine expansion qui révolutionne de nombreux secteurs d’activité. Les modèles de langage de grande taille (LLM) sont l’une des avancées les plus marquantes dans le domaine du traitement automatique du langage naturel. Pour tirer pleinement parti de ces modèles, il est essentiel de disposer de ressources matérielles adaptées, notamment des cartes graphiques performantes. Dans ce guide, je vous propose de découvrir comment provisionner des fGPU chez OUTSCALE.
L’importance des cartes graphiques dans les LLM
Section intitulée « L’importance des cartes graphiques dans les LLM »Les modèles de langage de grande taille (LLM) sont des réseaux de neurones profonds qui nécessitent d’importantes ressources de calcul pour fonctionner correctement. Les cartes graphiques, ou GPU (Graphic Processing Units), sont particulièrement adaptées à ce type de tâches, car elles sont conçues pour traiter rapidement un grand nombre d’opérations en parallèle.
Les GPU sont capables d’exécuter des milliers de threads simultanément, ce qui les rend idéales pour les calculs matriciels, une opération courante dans les réseaux de neurones. Cette capacité de traitement parallèle permet d’accélérer considérablement les temps de calcul et d’entraînement des LLM, par rapport à l’utilisation de processeurs centraux (CPU) traditionnels.
Les LLM nécessitent également une grande quantité de mémoire pour stocker les poids des neurones et les données intermédiaires. Les cartes graphiques modernes disposent de mémoires dédiées, appelées VRAM (Video Random Access Memory), qui offrent des capacités et des débits élevés. Une VRAM suffisante est essentielle pour traiter efficacement les LLM et éviter les problèmes de saturation de la mémoire, qui peuvent entraîner une dégradation des performances ou des erreurs de calcul.
Les principales bibliothèques et frameworks d’IA, tels que TensorFlow, PyTorch ou Caffe, sont optimisés pour tirer parti des GPU. Ces outils prennent en charge les instructions spécifiques aux GPU, comme CUDA pour les cartes graphiques Nvidia et permettent d’exploiter pleinement leurs capacités de calcul.
Choisir la bonne carte graphique pour les LLM
Section intitulée « Choisir la bonne carte graphique pour les LLM »Pour tirer le meilleur parti des modèles de LLM, il est important de choisir une carte graphique adaptée à vos besoins. Voici quelques critères à prendre en compte lors de votre sélection.
La performance de calcul d’un GPU est généralement mesurée en FLOPS (FLoating-point Operations Per Second). Plus le nombre de FLOPS est élevé, plus la carte graphique est capable d’effectuer rapidement des opérations en virgule flottante, ce qui est essentiel pour les LLM. Les GPU haut de gamme offrent des performances de calcul supérieures, mais ils sont également plus coûteux. Il est important de trouver un équilibre entre les performances et le budget.
Comme mentionné précédemment, la mémoire vidéo (VRAM) est un facteur important pour le traitement des LLM. Assurez-vous de choisir une carte graphique avec une quantité de VRAM suffisante pour stocker les poids des neurones et les données intermédiaires de vos modèles. En général, plus la taille des modèles que vous souhaitez utiliser est grande, plus vous aurez besoin de VRAM.
Vérifiez que la carte graphique que vous choisissez est compatible avec les bibliothèques et les frameworks d’IA que vous utilisez. Par exemple, si vous travaillez avec TensorFlow ou PyTorch, assurez-vous que la carte graphique prend en charge CUDA si vous optez pour une carte Nvidia.
Les cartes graphiques consomment généralement beaucoup d’énergie, surtout lorsqu’elles sont sollicitées par des tâches exigeantes comme l’entraînement de LLM. Il est important de prendre en compte la consommation d’énergie et le système de refroidissement de la carte graphique pour éviter les problèmes de surchauffe et garantir une durée de vie optimale du matériel.
Enfin, tenez compte du rapport qualité-prix lors du choix d’une carte graphique pour les LLM. Les cartes graphiques haut de gamme offrent des performances supérieures, mais elles peuvent être hors de portée pour certains budgets. Il est important de trouver une carte graphique qui offre un bon compromis entre performances, fonctionnalités et coût.
En résumé, les cartes graphiques jouent un rôle important dans l’utilisation des modèles LLM. Leur capacité à traiter rapidement un grand nombre d’opérations en parallèle, leur mémoire dédiée et l’optimisation des bibliothèques et des frameworks d’IA pour les GPU font d’elles un composant essentiel pour les applications d’intelligence artificielle.
Les fGPU OUTSCALE
Section intitulée « Les fGPU OUTSCALE »Les fGPU (flexible GPU) sont des ressources du cloud conçues pour gérer le rendu graphique et les calculs parallèles intensifs. Vous avez la possibilité d’allouer des fGPU à votre compte et de les associer ou dissocier facilement de vos machines virtuelles (VM) en fonction de vos besoins.
Etat d’un fGPU OUTSCALE
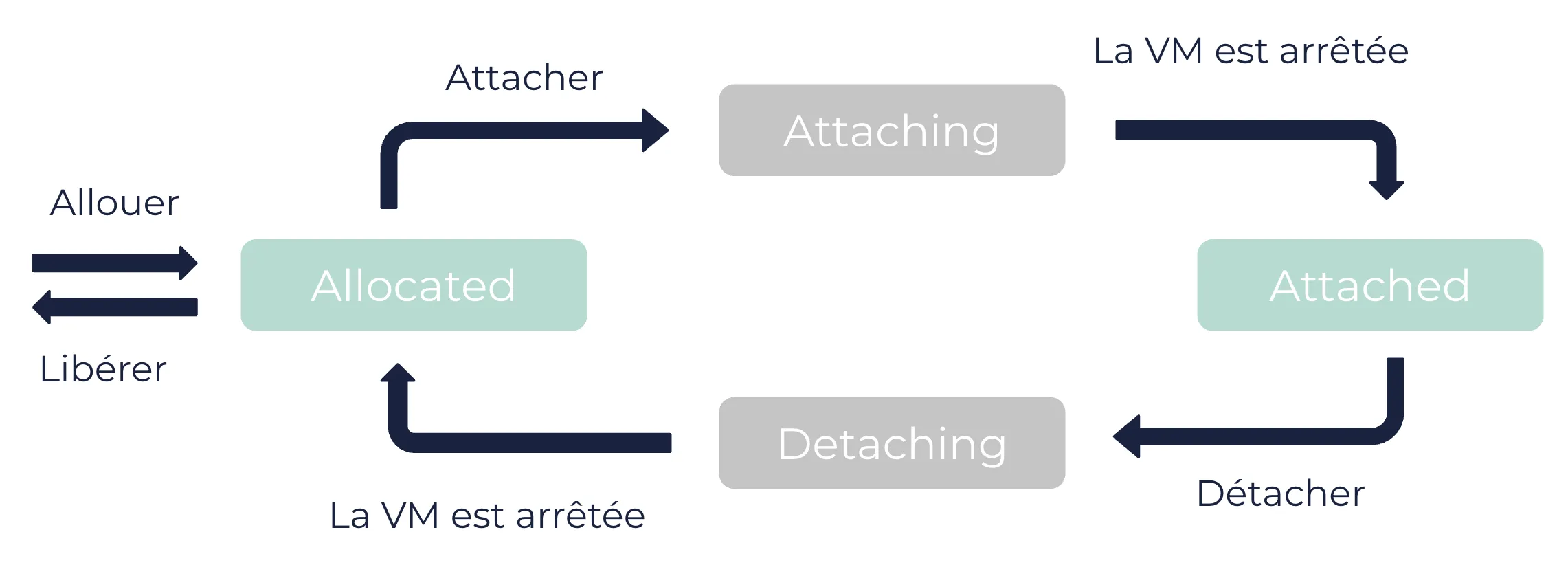
Section intitulée « Etat d’un fGPU OUTSCALE »Un fGPU est une ressource que vous pouvez allouer à votre compte et connecter ou déconnecter de vos machines virtuelles (VM) selon vos besoins. Il est possible de connecter plusieurs fGPU à une même VM, à condition qu’ils soient du même modèle.
Le fGPU peut se trouver dans différents états :
- alloué : le fGPU est réservé pour votre compte.
- en cours de connexion : la connexion du fGPU à une VM est prévue. Vous devez arrêter la VM pour que le fGPU passe à l’état connecté.
- connecté : le fGPU est utilisé par la VM. Il est considéré comme un périphérique connecté à la VM.
- en cours de déconnexion : la déconnexion du fGPU est prévue. Vous devez arrêter la VM pour que le fGPU passe à l’état alloué.
Les Modèles de fGPU Disponibles
Section intitulée « Les Modèles de fGPU Disponibles »OUTSCALE propose une gamme complète de cartes fGPU pour répondre aux besoins des différentes applications. Les modèles disponibles actuellement sont conçus pour offrir des performances optimales en matière de rendu graphique et de calculs parallèles lourds.
| Modèle de fGPU | VRAM du fGPU (en Mio) | Nombre maximum de vCores | Quantité maximum de mémoire (en Gio) | Générations de processeur compatibles | Régions |
|---|---|---|---|---|---|
| nvidia-a100 | 40000 | 35 | 250 | v5, v6 | eu-west-2 |
| nvidia-a100-80 | 80000 | 35 | 256 | v6 | eu-west-2, cloudgouv-eu-west-1 |
| nvidia-k2 | 4096 | 80 | 512 | v3, v4 | eu-west-2, us-east-2, us-west-1 |
| nvidia-m60 | 16000 | 80 | 512 | v3, v4 | eu-west-2 |
| nvidia-p6 | 16000 | 80 | 512 | v5 | eu-west-2, cloudgouv-eu-west-1, us-east-2, us-west-1, ap-northeast-1 |
| nvidia-p100 | 16000 | 80 | 512 | v5 | eu-west-2, us-east-2, us-west-1 |
| nvidia-v100 | 16000 | 35 | 250 | v5 | eu-west-2 |
| nvidia-l40 | 48000 | 35 | 240 | v7 | eu-west-2 |
Pour obtenir la liste des cartes disponibles dans une région, vous pouvez
utiliser la commande osc-cli suivante :
osc-cli api ReadFlexibleGpuCatalog --profile "default"
{ "ResponseContext": { "RequestId": "acaa0c91-3e5a-4959-912c-a5dd1f37cc3f" }, "FlexibleGpuCatalog": [ { "VRam": 40000, "Generations": [ "v5", "v6" ], "MaxCpu": 35, "MaxRam": 250, "ModelName": "nvidia-a100" }, { "VRam": 4096, "Generations": [ "v3", "v4" ], "MaxCpu": 80, "MaxRam": 512, "ModelName": "nvidia-k2" }, { "VRam": 16000, "Generations": [ "v5" ], "MaxCpu": 80, "MaxRam": 512, "ModelName": "nvidia-p100" }, { "VRam": 16000, "Generations": [ "v5" ], "MaxCpu": 80, "MaxRam": 512, "ModelName": "nvidia-p6" }, { "VRam": 16000, "Generations": [ "v5" ], "MaxCpu": 35, "MaxRam": 250, "ModelName": "nvidia-v100" }, { "VRam": 80000, "Generations": [ "v6" ], "MaxCpu": 35, "MaxRam": 256, "ModelName": "nvidia-a100-80" }, { "VRam": 24000, "Generations": [ "v5", "v6" ], "MaxCpu": 35, "MaxRam": 250, "ModelName": "nvidia-a10" }, { "VRam": 16000, "Generations": [ "v3", "v4" ], "MaxCpu": 80, "MaxRam": 512, "ModelName": "nvidia-m60" }, { "VRam": 48000, "Generations": [ "v7" ], "MaxCpu": 35, "MaxRam": 250, "ModelName": "nvidia-l40" } ]}Provisionnement de fGPU chez OUTSCALE
Section intitulée « Provisionnement de fGPU chez OUTSCALE »Dans ce chapitre, nous allons voir comment provisionner et attacher des fGPU aux machines virtuelles (VM) à l’aide de Terraform et de l’outil en ligne de commande OSC-CLI fourni par OUTSCALE.
Tout d’abord, assurez-vous d’avoir installé Terraform et OSC-CLI sur votre poste de travail.
Il est également possible de réaliser ces tâches depuis Cockpit, mais ce ne sera pas documenté ici.
Provisionnement avec Terraform
Section intitulée « Provisionnement avec Terraform »Créez un fichier de configuration Terraform pour définir les ressources nécessaires. Dans ce fichier, vous pouvez définir les fGPU à provisionner et les VM auxquelles ils seront attachés.
Voici un exemple de fichier de configuration :
resource "OUTSCALE_flexible_gpu" "flexible_gpu01" { model_name = var.model_name generation = "v4" subregion_name = "${var.region}a" delete_on_vm_deletion = true- Exécutez la commande
terraform initpour initialiser le répertoire de travail Terraform. - Exécutez la commande
terraform applypour créer les ressources définies dans le fichier de configuration. Cette commande provisionnera le fGPU. - Vous pouvez vérifier l’état des ressources à l’aide de la commande
terraform show. Cette commande affiche les détails des ressources créées, y compris l’état du fGPU. - Une fois que vous avez terminé d’utiliser les ressources, vous pouvez les
supprimer à l’aide de la commande
terraform destroy. Cette commande supprimera le fGPU.
Provisionnement avec osc-cli
Section intitulée « Provisionnement avec osc-cli »Vous pouvez également utiliser osc-cli pour gérer les fGPU. Voici
les principales commandes :
- Pour créer un fGPU :
osc-cli api CreateFlexibleGpu --profile "default" \ --ModelName "nvidia-p100" \ --Generation "v5" \ --SubregionName "eu-west-2a" \ --DeleteOnVmDeletion True- Pour attacher un fGPU à une VM :
osc-cli api LinkFlexibleGpu --profile "default" \ --FlexibleGpuId "fgpu-12345678" \ --VmId "i-12345678"- Pour détacher un* fGPU* d’une VM :
osc-cli api UnlinkFlexibleGpu --profile "default" \ --FlexibleGpuId "fgpu-12345678"- Pour libérer un fGPU :
osc-cli api DeleteFlexibleGpu --profile "default" \ --FlexibleGpuId "fgpu-12345678"Installation des drivers Nvidia et du toolkit CUDA
Section intitulée « Installation des drivers Nvidia et du toolkit CUDA »Pour pouvoir utiliser les fGPU, il faut bien sur installer et configurer correctement le système d’exploitation de la VM. Je vais vous donner le playbook que j’utilise pour réaliser cette tâche et ce spécifiquement pour une distribution Ubuntu 22.04.
Voici un exemple de playbook réalisant cette tâche :
---* name: Install nvidia drivers On Ubuntu 22.04 hosts: packer-nvidia gather_facts: true vars: kernel_version: "6.2" cuda_drivers_version: "550" tasks: - name: Upgrade packages ansible.builtin.apt: force_apt_get: true update_cache: true upgrade: true cache_valid_time: 3600 become: true - name: Get list of files mainline kernel ansible.builtin.uri: url: "https://kernel.ubuntu.com/mainline/v{{ kernel_version }}/amd64/" return_content: true register: list_files - name: Get list of packages deb ansible.builtin.set_fact: list_debs: '{{ list_files.content | regex_findall("linux[a-z0-9\-_\.]+\.deb") | unique }}' - name: Download mainline kernel become: true ansible.builtin.get_url: url: "https://kernel.ubuntu.com/mainline/v{{ kernel_version }}/amd64/{{ item }}" dest: /tmp/ owner: root group: root mode: "0644" loop: "{{ list_debs }}" - name: Install kernel packages become: true ansible.builtin.apt: deb: "/tmp/{{ item }}" with_items: - '{{ list_debs | regex_findall("linux-headers[a-z0-9\-_\.]+_all\.deb") | unique }}' - '{{ list_debs | regex_findall("linux-modules[a-z0-9\-_\.]+\.deb") | unique }}' - '{{ list_debs | regex_findall("linux-headers[a-z0-9\-_\.]+_amd64\.deb") | unique }}' - '{{ list_debs | regex_findall("linux-image[a-z0-9\-_\.]+_amd64\.deb") | unique }}' notify: Reboot Machine - name: Install Netwwork Nvidia Repo become: true ansible.builtin.get_url: url: https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb dest: /tmp/ owner: root group: root mode: "0644" - name: Install cuda repo become: true ansible.builtin.apt: deb: "/tmp/cuda-keyring_1.1-1_all.deb" - name: Install cuda-toolkit become: true ansible.builtin.apt: name: - cuda-toolkit - "cuda-drivers-{{ cuda_drivers_version }}" - nvtop state: present update_cache: true notify: Reboot Machine - name: Get Cuda Toolkit Version ansible.builtin.command: cmd: "/usr/local/cuda/bin/nvcc --version" changed_when: false register: nvcc_version - name: Get Version ansible.builtin.set_fact: cuda_toolkit_version: '{{ nvcc_version.stdout_lines | regex_findall("release (\d+\.\d+)+") }}' - name: Create profile script become: true ansible.builtin.file: path: /etc/profile.d/nvidia.sh state: touch owner: root group: root mode: "0644" - name: Add PATH to user OUTSCALE become: true ansible.builtin.lineinfile: regex: "export PATH=/usr/local/cuda-{{ cuda_toolkit_version | first }}/bin${PATH:+:${PATH}}" line: "export PATH=/usr/local/cuda-{{ cuda_toolkit_version | first }}/bin${PATH:+:${PATH}}" path: /etc/profile.d/nvidia.sh - name: Add LIBPATH to user OUTSCALE become: true ansible.builtin.lineinfile: regex: "export LD_LIBRARY_PATH=/usr/local/cuda-{{ cuda_toolkit_version }}/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}" line: "export LD_LIBRARY_PATH=/usr/local/cuda-{{ cuda_toolkit_version }}/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}" path: /etc/profile.d/nvidia.sh handlers: - name: Reboot Machine become: true ansible.builtin.reboot: msg: "Rebooting..."Pour vérifier le bon fonctionnement de votre carte graphique, vous pouvez utiliser les commandes suivantes :
nvcc --versionnvcc: NVIDIA (R) Cuda compiler driverCopyright (c) 2005-2024 NVIDIA CorporationBuilt on Tue_Feb_27_16:19:38_PST_2024Cuda compilation tools, release 12.4, V12.4.99Build cuda_12.4.r12.4/compiler.33961263_0
# ou
nvidia-smiFri May 3 08:26:26 2024+-----------------------------------------------------------------------------------------+| NVIDIA-SMI 550.67 Driver Version: 550.67 CUDA Version: 12.4 ||-----------------------------------------+------------------------+----------------------+| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. || | | MIG M. ||=========================================+========================+======================|| 0 NVIDIA A100 80GB PCIe Off | 00000000:00:0C.0 Off | 0 || N/A 36C P0 45W / 300W | 1MiB / 81920MiB | 0% Default || | | Disabled |+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+| Processes: || GPU GI CI PID Type Process name GPU Memory || ID ID Usage ||=========================================================================================|| No running processes found |+-----------------------------------------------------------------------------------------+Pour suivre la charge de fGPU, vous pouvez installer l’utilitaire nvtop :
Conclusion
Section intitulée « Conclusion »En conclusion, le provisionnement de fGPU pour l’utilisation des LLM (Large-Scale Machine Learning) chez OUTSCALE est une solution efficace pour améliorer les performances de calcul et réduire les coûts. Les modèles de cartes fGPU disponibles chez OUTSCALE offrent une grande flexibilité pour répondre aux besoins spécifiques des entreprises.
L’adoption du provisionnement de fGPU dans le cloud OUTSCALE présente de nombreux avantages pour les entreprises :
- Flexibilité : Accédez à des ressources fGPU à la demande, en fonction de vos besoins fluctuants, sans investissement initial important.
- Évolutivité : Augmentez ou diminuez facilement la capacité de calcul fGPU en fonction de l’évolution de vos charges de travail.
- Réduction des coûts : Évitez les dépenses liées à l’achat et à la maintenance de matériel fGPU onéreux.
- Opération simplifiée : Déléguez la gestion de l’infrastructure fGPU au fournisseur de cloud, vous libérant ainsi pour vous concentrer sur vos tâches critiques.
- Accès à la dernière technologie : Bénéficiez des dernières innovations en matière de fGPU sans avoir à mettre à niveau votre matériel en permanence.
De plus, grâce à l’utilisation de Terraform et de l’outil en ligne de commande OSC-CLI, le provisionnement et l’attachement des fGPU aux machines virtuelles sont simplifiés et automatisés. Les administrateurs système peuvent ainsi se concentrer sur d’autres tâches à valeur ajoutée pour leur entreprise.
En somme, le provisionnement de fGPU pour les LLM chez OUTSCALE est une solution performante et économique pour les entreprises souhaitant se lancer dans l’Intelligence Artificielle.