![]()
Ce guide vous accompagne dans votre première connexion à la console CAST AI. Vous découvrirez les écrans principaux et ce qu’ils vous apprennent sur votre cluster.
Combien de temps attendre ?
Section intitulée « Combien de temps attendre ? »Après l’installation de CAST AI sur votre cluster, les données arrivent progressivement :
| Temps écoulé | Ce que vous voyez dans la console |
|---|---|
| < 2h | Score d’optimisation à 0, pas de recommandations |
| 2-6h | Premières métriques, recommandations très conservatrices (max 10-25% d’ajustement) |
| 6-24h | Recommandations partielles, confiance “Low” sur la plupart des workloads |
| 24-48h | Recommandations fiables pour les workloads stables, confiance “Full” qui apparaît |
| 3-7 jours | Confiance “Full” sur la majorité des workloads, patterns hebdomadaires captés |
Pourquoi attendre ?
Section intitulée « Pourquoi attendre ? »CAST AI observe l’utilisation réelle de vos workloads avant de recommander des ajustements. Un workload peut :
- Avoir des pics de charge à certaines heures
- Consommer différemment en semaine et le week-end
- Démarrer avec beaucoup de ressources (Java, .NET) puis se stabiliser
Sans historique, les recommandations seraient hasardeuses.
Le “gradual scaling” des premières 24h
Section intitulée « Le “gradual scaling” des premières 24h »Pour les nouveaux clusters, CAST AI applique des ajustements progressifs et limités :
| Période | Ajustement maximum |
|---|---|
| < 2h | 10% des ressources actuelles |
| 2-6h | 25% des ressources actuelles |
| 6-24h | 35% des ressources actuelles |
| > 24h | Selon le niveau de confiance |
C’est une protection : CAST AI préfère être conservateur plutôt que de casser vos workloads.
Se connecter à la console
Section intitulée « Se connecter à la console »-
Ouvrez console.cast.ai dans votre navigateur
-
Connectez-vous avec votre compte (Google, GitHub ou email)
L’écran d’accueil : la liste des clusters
Section intitulée « L’écran d’accueil : la liste des clusters »Après connexion, vous voyez la liste de vos clusters. Chaque ligne affiche :
- Nom du cluster : celui que vous avez donné lors de l’installation
- Provider : le cloud ou l’environnement (AWS, GCP, Azure, ou “Anywhere” pour les autres)
- État : Connected (vert) si l’agent communique avec CAST AI
- Score: le score d’optimisation global du cluster (0-10)
- Savings : les économies potentielles détectées
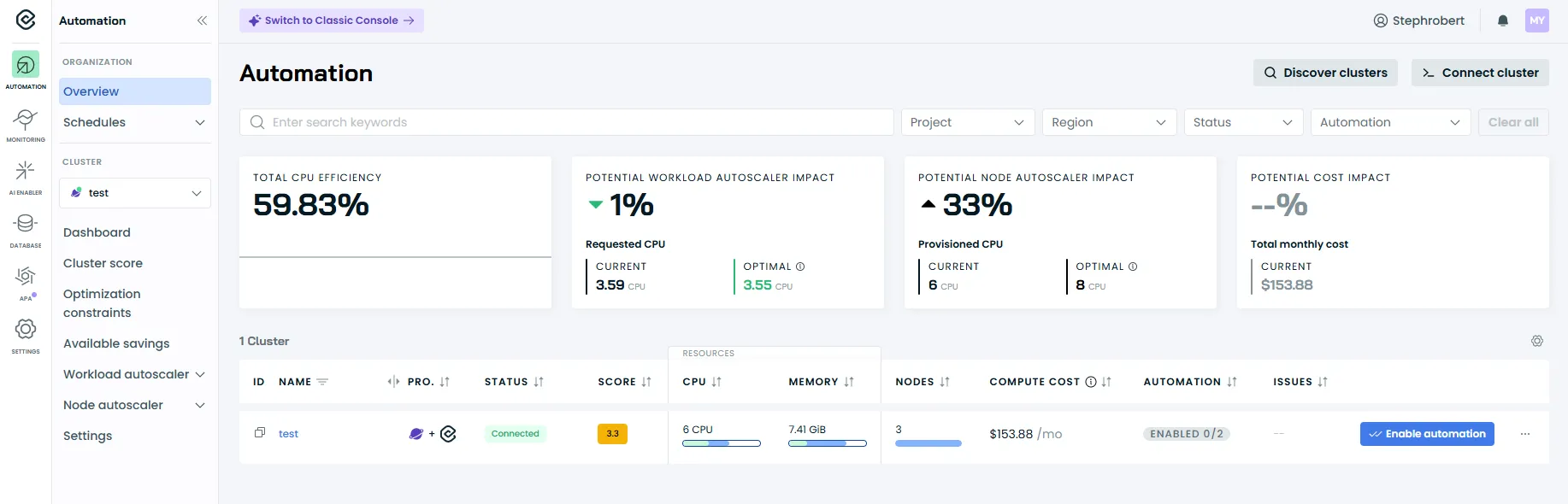
Cliquez sur un cluster pour accéder à son tableau de bord.
Le tableau de bord du cluster
Section intitulée « Le tableau de bord du cluster »C’est l’écran principal d’un cluster. Il répond à une question simple : quel est l’état de mon cluster ?
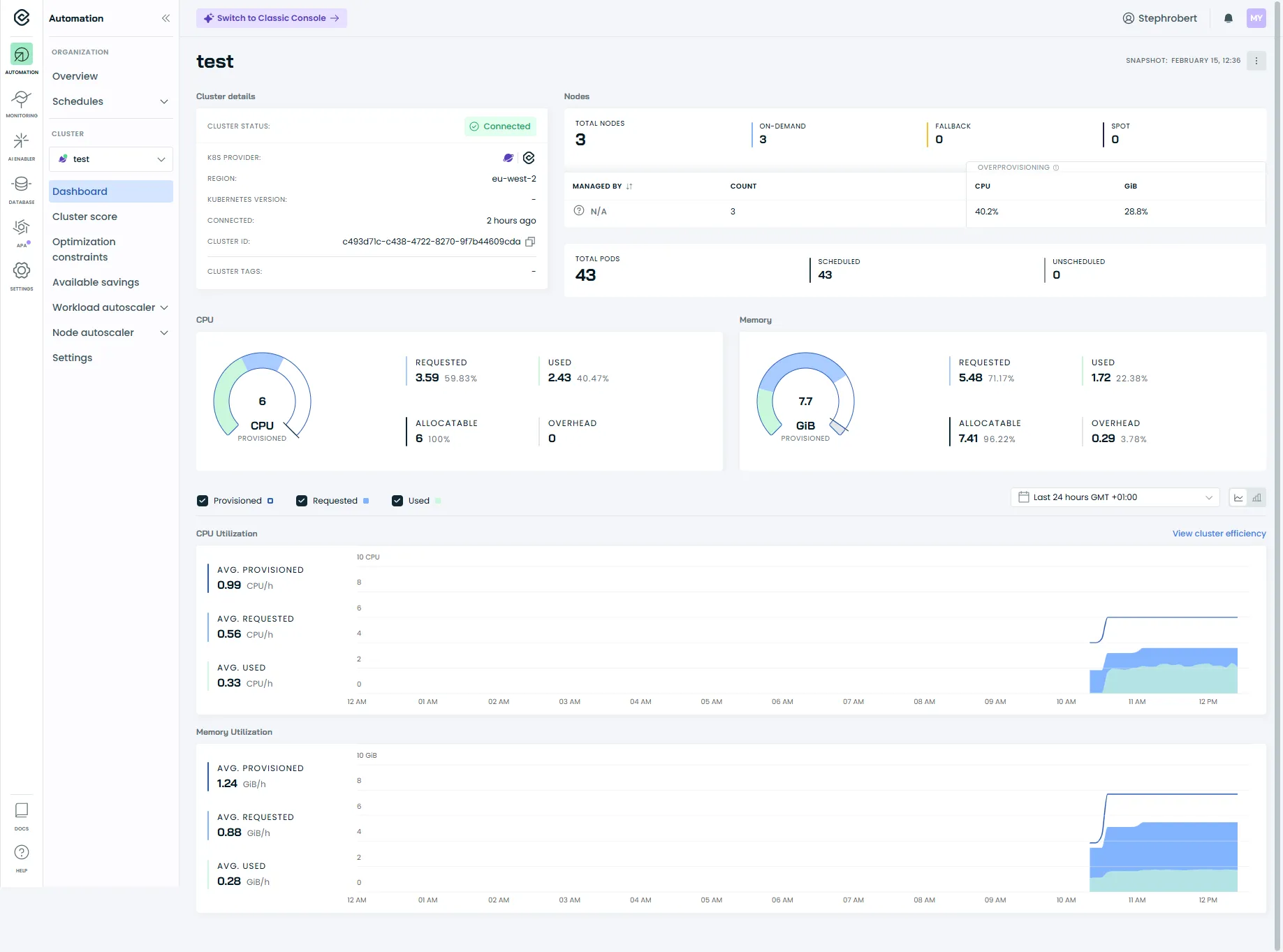
Les informations du dashboard
Section intitulée « Les informations du dashboard »Le dashboard affiche en un coup d’œil :
- Cluster details : statut de connexion, provider Kubernetes, région, ID du cluster
- Nodes : nombre total de nœuds, répartition on-demand/spot/fallback
- Resources : CPUs et mémoire provisionnés vs demandés (requests)
- Pods : nombre total de pods, scheduled et unscheduled
Le bas du dashboard montre les tendances sur 24h, 7 jours et 30 jours.
Les liens de navigation
Section intitulée « Les liens de navigation »À partir du dashboard, vous accédez aux sections principales via le menu de gauche :
| Section | Ce qu’elle contient |
|---|---|
| Cluster Score | Le score d’optimisation du cluster (0-10) |
| Optimization Constraints | Les restrictions détectées sur les workloads (ex. pas de probes) |
| Available Savings | Les économies potentielles détectées par CAST AI |
| Workload Autoscaler | Liste des workloads, scaling policies |
| Nodes Autoscaler | Configuration de l’autoscaling des nœuds |
| Settings | Paramètres du cluster |
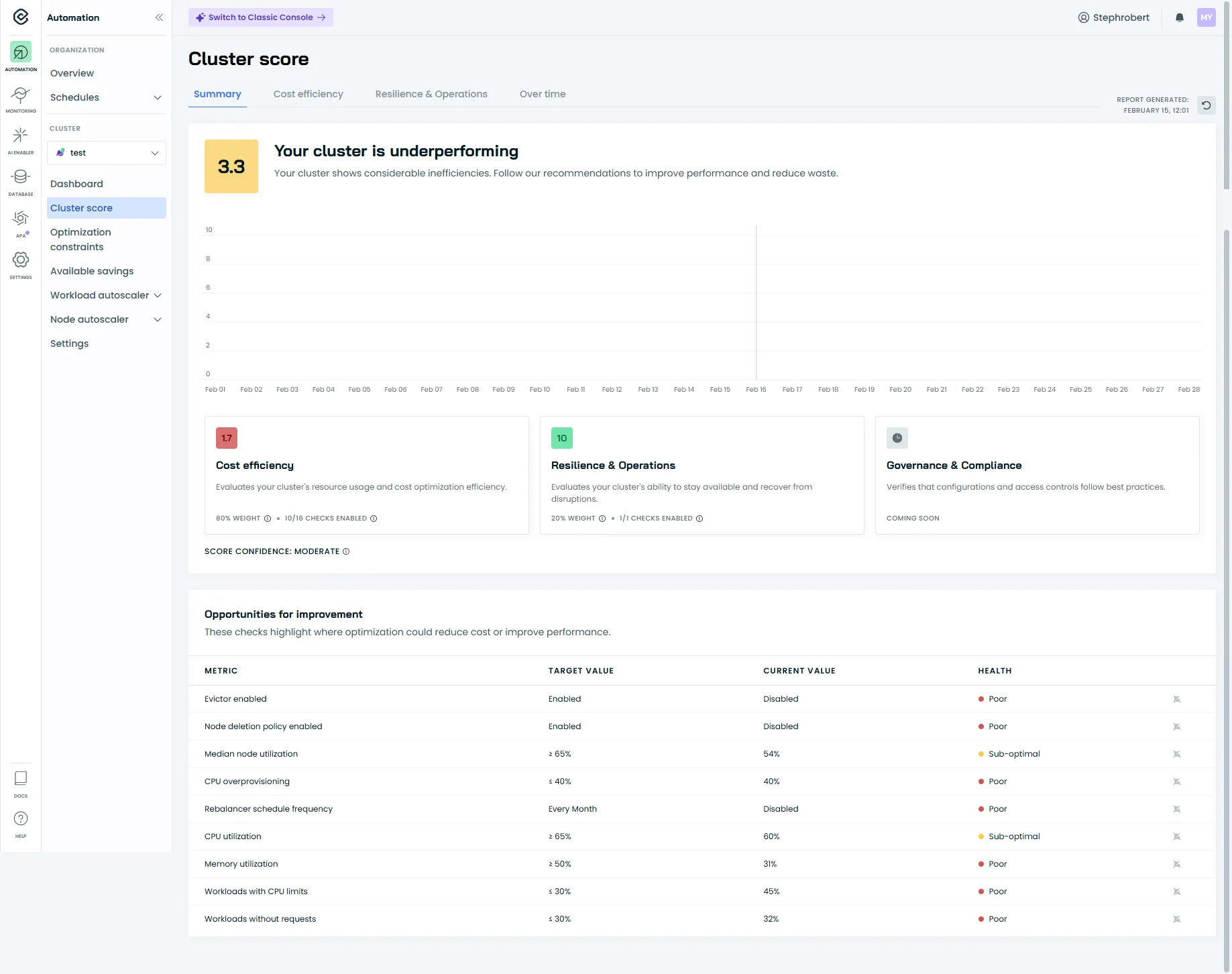
Le Cluster Score
Section intitulée « Le Cluster Score »Le Cluster Score est accessible via le menu Cost Monitoring → Cluster score ou Cluster Overview → Score.
C’est une évaluation globale de l’optimisation de votre cluster sur une échelle de 0 à 10.
Comprendre le score
Section intitulée « Comprendre le score »| Score | État | Ce que ça signifie |
|---|---|---|
| 7-10 | 🟢 Healthy | Ressources bien optimisées |
| 4-6 | 🟡 Concerning | Marge d’amélioration significative |
| 0-3 | 🔴 Poor | Sur-provisionnement important |
Un score bas n’est pas une erreur : c’est normal quand on démarre. Le score s’améliore progressivement avec les optimisations.
Les Optimization Constraints
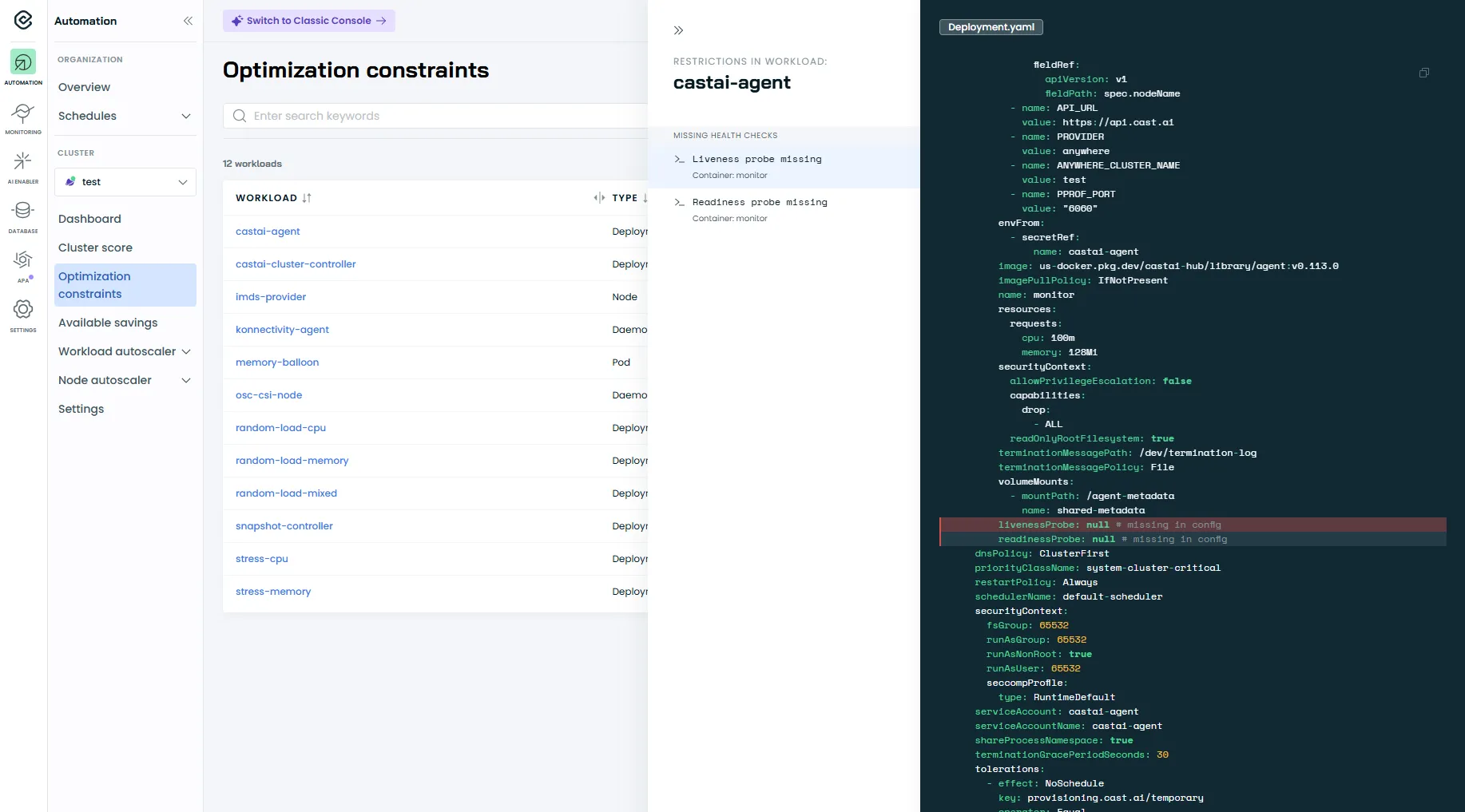
Section intitulée « Les Optimization Constraints »L’écran Optimization constraints liste les workloads et les restrictions détectées par CAST AI qui peuvent rendre l’automatisation plus risquée.
En sélectionnant un workload, la console affiche les restrictions dans le panneau de droite (ex. Missing health checks) et vous permet d’inspecter le YAML associé.
Dans l’exemple ci-dessous, CAST AI indique l’absence de readinessProbe et livenessProbe. Il est recommandé de configurer ces probes afin de fiabiliser le comportement des pods lors des redémarrages et des rollouts.
Les Available Savings
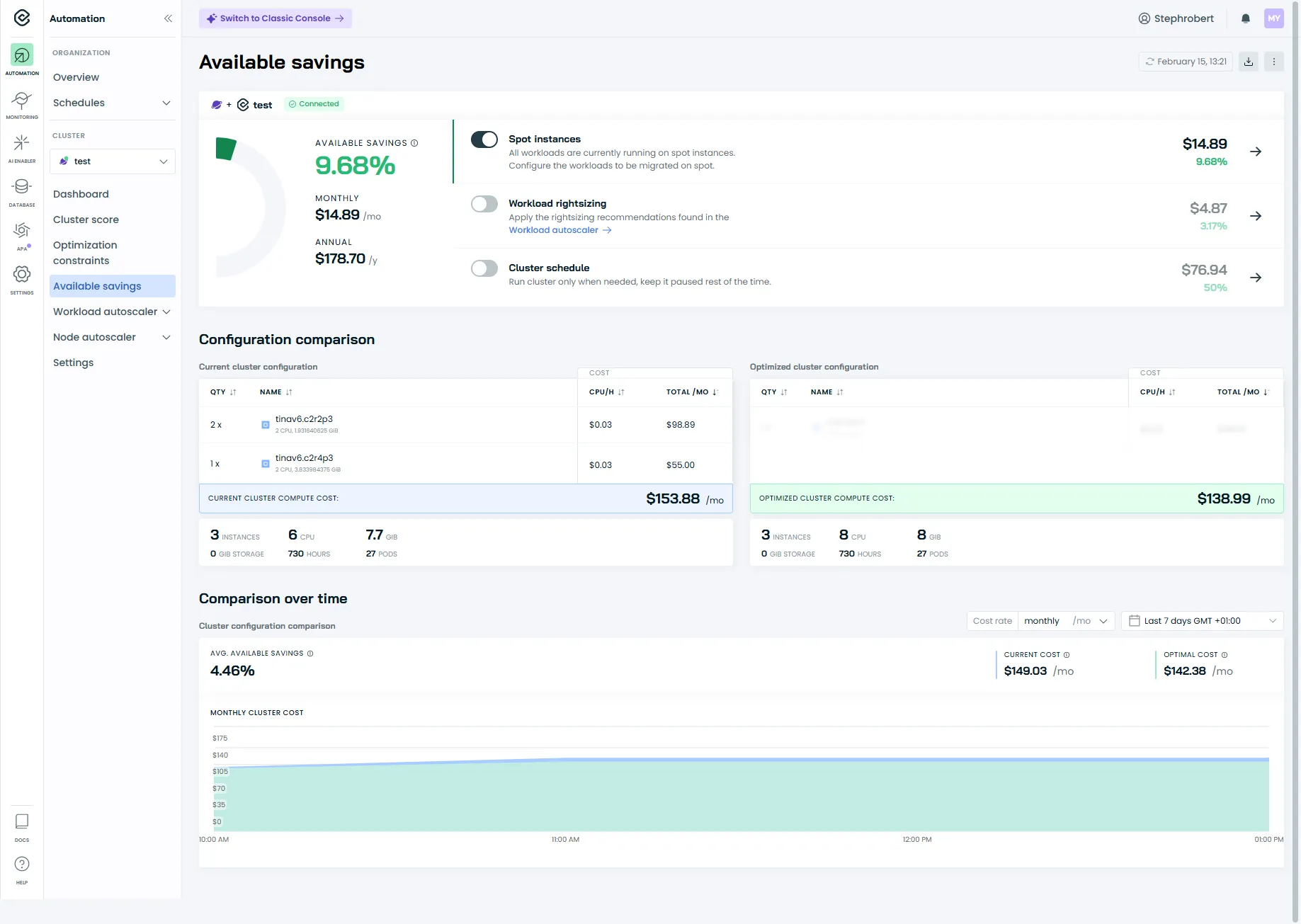
Section intitulée « Les Available Savings »L’écran Available Savings montre les économies potentielles détectées par CAST AI.
Ce rapport présente :
- Estimated savings : l’économie totale possible si vous appliquez toutes les recommandations
- Current cost : le coût estimé actuel de votre cluster
- Optimized cost : le coût après optimisation
Le rapport détaille aussi les économies par catégorie :
| Source d’économie | Ce qu’elle représente |
|---|---|
| Workload rightsizing | Réduction des requests CPU/memory sur-dimensionnées |
| Spot Instances | Utilisation d’instances spot (interruptibles, moins chères) |
La section Workload Autoscaler
Section intitulée « La section Workload Autoscaler »La section Workload Autoscaler est le cœur de l’optimisation au niveau des workloads : elle pilote comment CAST AI analyse l’usage réel, génère des recommandations et (selon ta stratégie) les applique automatiquement.
Tu y retrouves en général 4 entrées :
| Menu | À quoi ça sert | Quand y aller |
|---|---|---|
| Optimization | Voir les workloads agrégés (Deployment/StatefulSet…), leurs recommandations, et ajuster la configuration au niveau policy ou workload. | Quand tu veux comprendre “quoi optimiser” et “avec quel niveau de confiance”. ([Cast AI][3]) |
| Scaling policies | Gérer les policies (système + custom), leur mode d’application et leur automatisation. | Quand tu veux créer une policy “prod conservative” vs “dev agressive”. ([Cast AI][1]) |
| Impact | Vue orientée “effet” (impact de l’optimisation et des choix de policies). | Quand tu veux valider que l’automatisation produit un résultat mesurable (et pas juste des recommandations). |
| Event log | Historique des actions du Workload Autoscaler, utile pour diagnostiquer. | Quand “ça n’a pas été appliqué” ou pour comprendre un changement. ([Cast AI][4]) |
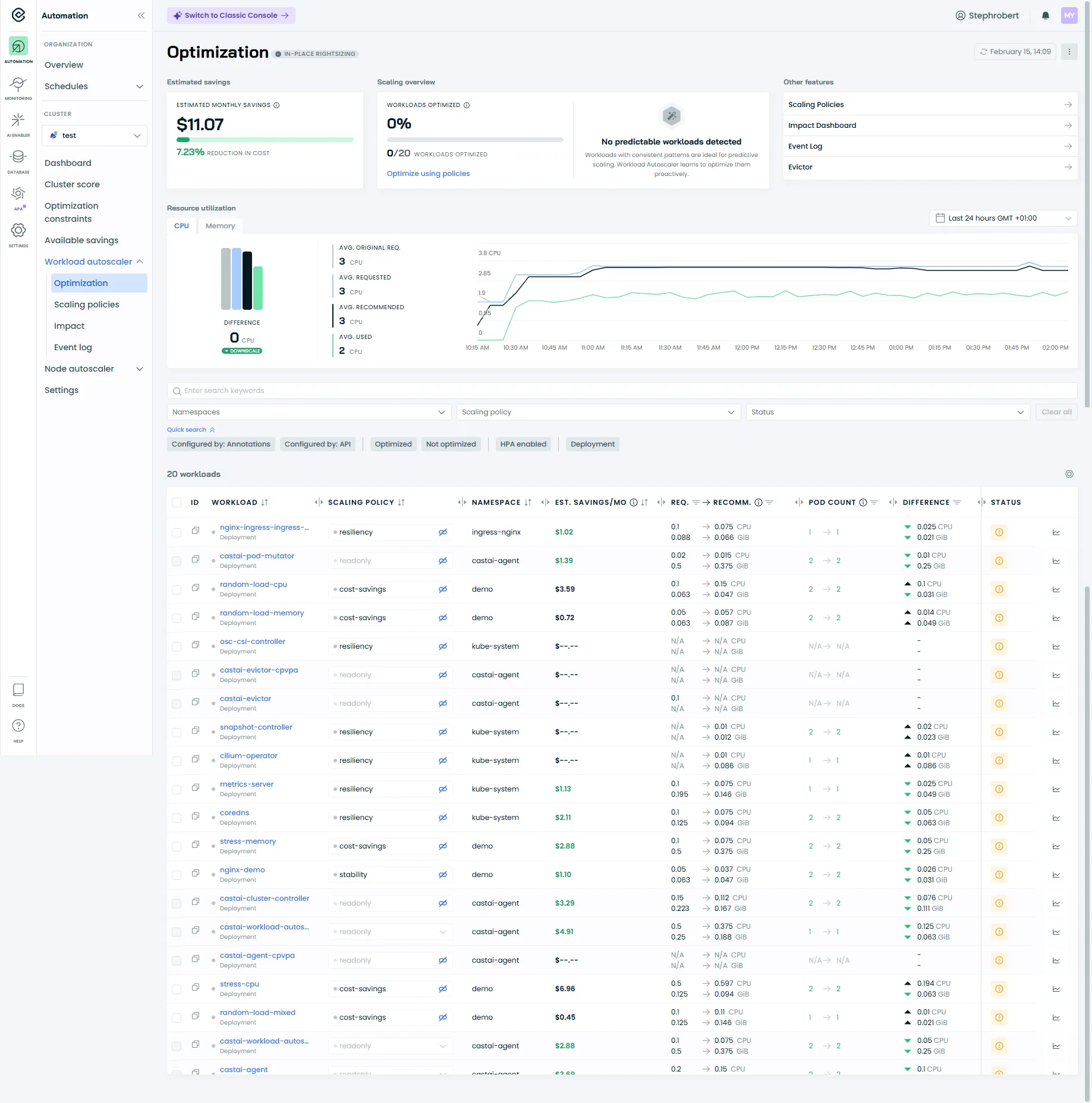
Optimization : ce que tu dois regarder en premier
Section intitulée « Optimization : ce que tu dois regarder en premier »Dans Optimization, commence par vérifier :
-
Les workloads “regroupés” : CAST AI agrège les pods sous leur contrôleur principal (Deployment, StatefulSet, etc.) pour te donner une vue exploitable.
-
Le niveau de confiance : un workload récent ou peu actif donnera des recommandations moins fiables au début. (Tu as déjà bien cadré l’idée dans ton intro “attendre”).
-
Le mode d’application : selon la policy, les changements peuvent être appliqués immédiatement ou attendre un redémarrage naturel.
Scaling policies : où tu fixes ton “style d’optimisation”
Section intitulée « Scaling policies : où tu fixes ton “style d’optimisation” »Les scaling policies définissent comment CAST AI calcule et applique le rightsizing (fonction CPU/mémoire, overhead, seuils, automation, apply mode…).
Tu peux :
- utiliser des policies système comme base,
- dupliquer une policy puis ajuster les paramètres,
- et, si dispo sur ton tenant, définir des règles d’assignation pour affecter automatiquement une policy à certains workloads.
La section Nodes Autoscaler
Section intitulée « La section Nodes Autoscaler »Le menu Nodes Autoscaler concerne l’optimisation au niveau des nœuds (capacité du cluster), c’est-à-dire comment l’autoscaler ajoute/supprime des nodes et quels garde-fous le contraignent.
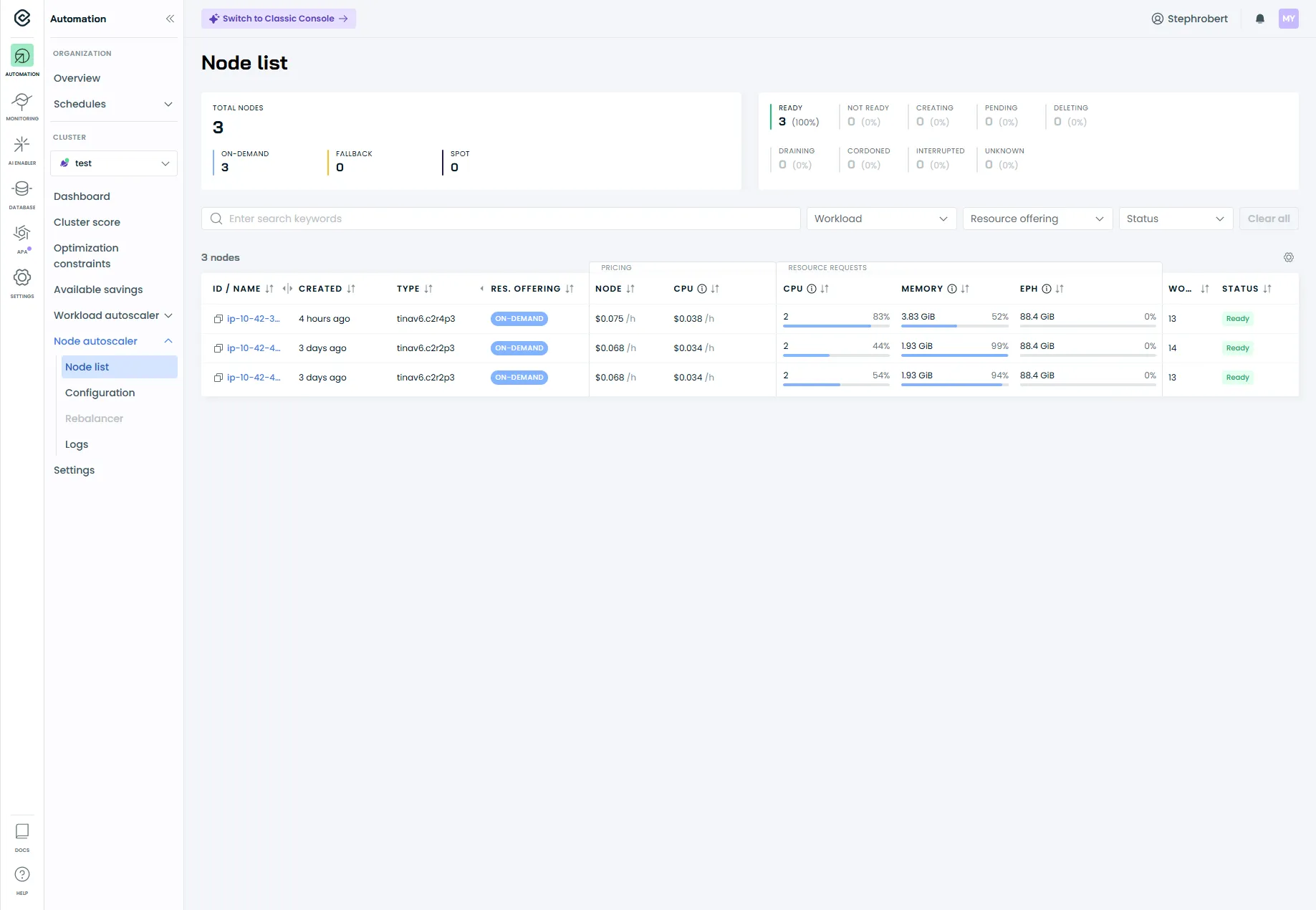
Autoscaler settings (garde-fous)
Section intitulée « Autoscaler settings (garde-fous) »Un réglage documenté et utile : Cluster CPU limits policy.
Il permet de définir une borne min/max sur la quantité totale de vCPU disponible sur l’ensemble des nœuds workers (pratique pour éviter une montée “incontrôlée” ou un scale-down trop agressif).
Node configuration (config appliquée aux nœuds)
Section intitulée « Node configuration (config appliquée aux nœuds) »La page Node configuration sert à appliquer des paramètres au node pendant le provisioning.
Point clé : ça n’influence pas le placement des workloads — ça sert uniquement à appliquer une configuration système sur le node au moment où il est créé.
Le menu Settings
Section intitulée « Le menu Settings »Le menu Settings (icône ⚙️) donne accès aux paramètres globaux du cluster :
- Default Scaling Policy : la policy appliquée par défaut aux nouveaux workloads
- Excluded Namespaces : les namespaces ignorés par CAST AI (par défaut :
kube-system,kube-public,castai-agent)
Prochaines étapes
Section intitulée « Prochaines étapes »Dans les prochains guides, nous verrons comment :
- Configurer les Scaling Policies : créer des policies adaptées à vos environnements (prod vs dev)
- Activer l’automatisation : passer du mode read-only au mode managed en toute sécurité
- Analyser l’Event log : diagnostiquer quand une recommandation n’est pas appliquée
Ressources
Section intitulée « Ressources »- Documentation officielle CAST AI — Documentation complète