![]()
Ce guide vous permet de dimensionner correctement les ressources CPU et mémoire de vos pods Kubernetes en vous basant sur leur consommation réelle. Vous apprendrez à installer Goldilocks avec Helm, activer la surveillance sur vos namespaces et interpréter les recommandations. Goldilocks résout un problème universel : comment savoir quelle quantité de ressources allouer à vos applications sans sur-provisionner (gaspillage) ni sous-provisionner (instabilité).
Ce que vous allez apprendre
Section intitulée « Ce que vous allez apprendre »- Comprendre le problème du dimensionnement des ressources Kubernetes
- Installer Goldilocks et ses prérequis (VPA, metrics-server)
- Activer la surveillance sur vos namespaces
- Utiliser le dashboard pour visualiser les recommandations
- Interpréter les classes de qualité de service (QoS)
- Configurer les options avancées (update mode, exclusions)
Prérequis : un cluster Kubernetes fonctionnel avec kubectl configuré. Niveau intermédiaire en Kubernetes recommandé.
Qu’est-ce que Goldilocks ?
Section intitulée « Qu’est-ce que Goldilocks ? »Goldilocks est un outil open source développé par Fairwinds qui analyse la consommation réelle de vos pods Kubernetes et génère des recommandations de ressources basées sur des données objectives. Son nom fait référence au conte “Boucle d’Or” (Goldilocks en anglais) : tout comme la petite fille cherchait la bouillie “ni trop chaude, ni trop froide”, cet outil vous aide à trouver des ressources “ni trop grandes, ni trop petites” — juste ce qu’il faut.
Goldilocks s’appuie sur le Vertical Pod Autoscaler (VPA), un composant officiel de l’écosystème Kubernetes qui analyse l’historique de consommation des pods. L’outil crée automatiquement un VPA pour chaque workload d’un namespace surveillé, puis affiche les recommandations dans un dashboard web convivial.
| Situation | Sans Goldilocks | Avec Goldilocks |
|---|---|---|
| Définir les ressources | Estimation au doigt mouillé | Recommandations basées sur l’usage réel |
| Optimiser les coûts | Sur-provisionnement par sécurité | Juste ce qu’il faut, pas plus |
| Éviter les OOMKilled | Tests et erreurs en production | Limites ajustées à la consommation réelle |
| Documenter les choix | ”On a toujours fait comme ça” | Données objectives pour justifier |
Pourquoi le dimensionnement est difficile
Section intitulée « Pourquoi le dimensionnement est difficile »Chaque pod Kubernetes doit déclarer ses requests (ressources garanties) et ses limits (ressources maximales). Ces valeurs influencent directement la stabilité de vos applications et les coûts de votre cluster.
Le dilemme classique
Section intitulée « Le dilemme classique »Quand vous déployez une nouvelle application, vous êtes face à un choix impossible :
- Trop généreux : vous réservez 2 Go de RAM et 1 CPU “au cas où”. L’application n’en utilise que 200 Mo et 0.1 CPU. Résultat : 90% des ressources réservées sont gaspillées, votre cluster se remplit vite, vos factures cloud explosent.
- Trop conservateur : vous réservez 100 Mo de RAM pour économiser.
L’application a un pic de charge, dépasse sa limite et Kubernetes la tue avec
un
OOMKilled. Votre service est down. - Au hasard : vous copiez les valeurs d’un autre projet. Elles n’ont aucun rapport avec les besoins réels de votre application.
Ce que Goldilocks résout
Section intitulée « Ce que Goldilocks résout »Au lieu de deviner, Goldilocks observe votre application pendant qu’elle tourne et vous dit : “Cette application consomme en moyenne 150 Mo de RAM avec des pics à 300 Mo. Voici les requests et limits que je recommande.”
Cette approche data-driven remplace les estimations par des mesures objectives.
Comment fonctionne Goldilocks
Section intitulée « Comment fonctionne Goldilocks »L’architecture de Goldilocks repose sur trois composants qui travaillent ensemble pour collecter les métriques et générer des recommandations.
Les composants
Section intitulée « Les composants »- Metrics Server : Composant Kubernetes standard qui collecte les métriques CPU et mémoire de tous les pods du cluster. C’est la source de données brutes. Si vous n’avez pas metrics-server, aucune recommandation ne sera possible.
- Vertical Pod Autoscaler (VPA) : Projet officiel Kubernetes qui analyse l’historique des métriques et calcule des recommandations. Le VPA peut fonctionner en mode “recommandation seule” (il conseille sans modifier) ou en mode “auto” (il ajuste automatiquement les ressources). Goldilocks utilise par défaut le mode recommandation.
- Goldilocks Controller : Surveillance les namespaces labellisés et crée automatiquement un objet VPA pour chaque workload (Deployment, StatefulSet, DaemonSet). Sans ce controller, vous devriez créer manuellement un VPA par application.
- Goldilocks Dashboard : Interface web qui agrège les recommandations de tous les VPA et les présente de manière visuelle. Vous voyez d’un coup d’œil quels workloads sont sur-provisionnés ou sous-provisionnés.
Le flux de données
Section intitulée « Le flux de données »Le processus se déroule ainsi : metrics-server collecte les métriques toutes les quelques secondes → le VPA Recommender analyse ces données sur plusieurs jours → il génère des recommandations (target, lowerBound, upperBound) → le dashboard Goldilocks affiche ces valeurs de manière lisible.
Installation de base
Section intitulée « Installation de base »Goldilocks nécessite plusieurs composants. L’installation avec Helm simplifie considérablement le processus en gérant les dépendances automatiquement.
Prérequis
Section intitulée « Prérequis »Avant d’installer Goldilocks, vérifiez que votre cluster dispose des éléments suivants :
| Composant | Obligatoire | Vérification |
|---|---|---|
| kubectl | Oui | kubectl version |
| Helm | Recommandé | helm version |
| metrics-server | Oui | kubectl get apiservice v1beta1.metrics.k8s.io |
| Workloads existants | Oui | Des Deployments, StatefulSets ou DaemonSets à analyser |
Vérifiez que metrics-server fonctionne correctement :
kubectl get apiservice v1beta1.metrics.k8s.ioRésultat attendu :
NAME SERVICE AVAILABLE AGEv1beta1.metrics.k8s.io kube-system/metrics-server True 46hSi AVAILABLE affiche False (MissingEndpoints), installez ou réparez metrics-server avant de continuer.
Installation avec Helm (recommandée)
Section intitulée « Installation avec Helm (recommandée) »-
Ajouter le repository Helm Fairwinds
Fenêtre de terminal helm repo add fairwinds-stable https://charts.fairwinds.com/stablehelm repo updateCette commande ajoute le repository officiel de Fairwinds qui contient les charts Goldilocks et VPA.
-
Créer le namespace
Fenêtre de terminal kubectl create namespace goldilocksGoldilocks sera installé dans son propre namespace pour isoler ses composants.
-
Installer Goldilocks avec VPA
Fenêtre de terminal helm install goldilocks fairwinds-stable/goldilocks \--namespace goldilocks \--set vpa.enabled=trueL’option
vpa.enabled=trueinstalle automatiquement les composants VPA nécessaires. C’est la méthode la plus simple car elle évite d’installer VPA séparément. -
Vérifier l’installation
Fenêtre de terminal kubectl -n goldilocks get podsRésultat attendu :
NAME READY STATUS RESTARTS AGEgoldilocks-controller-7b9f8d6c4f-x2j9k 1/1 Running 0 2mgoldilocks-dashboard-5c7b9d8f6d-m4n5p 1/1 Running 0 2mgoldilocks-vpa-admission-controller-6f7a8b-k4l 1/1 Running 0 2mgoldilocks-vpa-recommender-6d7c8e9f5a-q3r4s 1/1 Running 0 2mVous devriez voir 4 pods : le controller Goldilocks, le dashboard, le VPA Recommender et le VPA Admission Controller.
Les 3 composants du VPA : qui fait quoi ?
Section intitulée « Les 3 composants du VPA : qui fait quoi ? »Le VPA installé par le chart Goldilocks est composé de trois sous-composants indépendants. Comprendre leur rôle est essentiel pour choisir le bon mode de fonctionnement :
| Composant | Installé par défaut | Rôle |
|---|---|---|
| Recommender | ✅ Oui | Analyse les métriques et calcule les recommandations CPU/mémoire |
| Admission Controller | ✅ Oui | Injecte les ressources recommandées dans les pods au moment de leur création (webhook) |
| Updater | ❌ Non | Évicte les pods en cours d’exécution pour forcer leur recréation avec les nouvelles ressources |
Concrètement, voici ce qui se passe selon le mode VPA choisi :
-
Mode
Off(le défaut) — Le Recommender calcule les recommandations, mais personne ne touche à vos pods. Vous consultez les valeurs dans le dashboard et vous les appliquez manuellement dans vos manifests. C’est le mode le plus sûr pour commencer. -
Mode
Initial— Le Recommender calcule, et l’Admission Controller injecte automatiquement les ressources recommandées dans les pods au moment de leur création. Si un pod est déjà en cours d’exécution, il garde ses anciennes valeurs jusqu’à son prochain redémarrage (rollout, crash, scaling…). -
Mode
Auto— CommeInitial, mais en plus l’Updater évicte activement les pods dont les ressources sortent de la plage recommandée pour forcer leur recréation avec les nouvelles valeurs. C’est le seul mode vraiment “automatique”.
Si vous activez le mode Auto (via le label
goldilocks.fairwinds.com/vpa-update-mode=auto) sans avoir installé
l’Updater, rien ne forcera le redémarrage de vos pods existants. Le
comportement sera identique au mode Initial. Voir la section Configuration
avancée pour activer l’Updater.
Activer la surveillance d’un namespace
Section intitulée « Activer la surveillance d’un namespace »Par défaut, Goldilocks n’analyse aucun namespace. Vous devez explicitement activer la surveillance avec un label. Cette approche opt-in évite de créer des VPA pour tous les workloads du cluster.
Labelliser un namespace
Section intitulée « Labelliser un namespace »Pour activer Goldilocks sur un namespace existant :
kubectl label namespace mon-namespace goldilocks.fairwinds.com/enabled=trueRemplacez mon-namespace par le nom de votre namespace (par exemple default, production, staging).
Vérification :
kubectl get namespace mon-namespace --show-labelsLe label goldilocks.fairwinds.com/enabled=true doit apparaître.
Ce qui se passe ensuite
Section intitulée « Ce qui se passe ensuite »Dès que le namespace est labellisé, le controller Goldilocks :
- Détecte le nouveau label
- Liste tous les workloads du namespace (Deployments, StatefulSets, DaemonSets)
- Crée un objet VPA pour chacun d’eux en mode
Off(recommandation uniquement) - Le VPA Recommender commence à collecter les métriques
Vérifiez que les VPA ont été créés :
kubectl -n mon-namespace get vpaExemple de résultat :
NAME MODE CPU MEM PROVIDED AGEgoldilocks-nginx Off 15m 262144k True 5mgoldilocks-api-server Off 50m 524288k True 5mActiver plusieurs namespaces
Section intitulée « Activer plusieurs namespaces »Vous pouvez activer plusieurs namespaces :
kubectl label namespace staging goldilocks.fairwinds.com/enabled=truekubectl label namespace production goldilocks.fairwinds.com/enabled=trueOu utiliser une boucle :
for ns in staging production monitoring; do kubectl label namespace $ns goldilocks.fairwinds.com/enabled=truedoneDésactiver la surveillance
Section intitulée « Désactiver la surveillance »Pour arrêter la surveillance d’un namespace :
kubectl label namespace mon-namespace goldilocks.fairwinds.com/enabled-Le tiret à la fin supprime le label. Goldilocks supprimera automatiquement les VPA qu’il avait créés.
Accéder au dashboard
Section intitulée « Accéder au dashboard »Le dashboard Goldilocks est une interface web qui affiche les recommandations de manière visuelle. Par défaut, il est exposé via un Service de type ClusterIP.
Port-forward (développement)
Section intitulée « Port-forward (développement) »La méthode la plus simple pour accéder au dashboard :
kubectl -n goldilocks port-forward svc/goldilocks-dashboard 8080:80Ouvrez ensuite votre navigateur à l’adresse http://localhost:8080.
Ingress (production)
Section intitulée « Ingress (production) »Pour un accès permanent, créez un Ingress :
apiVersion: networking.k8s.io/v1kind: Ingressmetadata: name: goldilocks namespace: goldilocks annotations: nginx.ingress.kubernetes.io/rewrite-target: /spec: ingressClassName: nginx rules: - host: goldilocks.example.com http: paths: - path: / pathType: Prefix backend: service: name: goldilocks-dashboard port: number: 80Ce que montre le dashboard
Section intitulée « Ce que montre le dashboard »Le dashboard liste tous les namespaces surveillés et tous les workloads qu’ils contiennent. Pour chaque workload, vous voyez :
- Le nom du Deployment/StatefulSet/DaemonSet
- Les ressources actuellement configurées (requests/limits)
- Les ressources recommandées par le VPA
- Deux colonnes : Guaranteed et Burstable (voir section suivante)
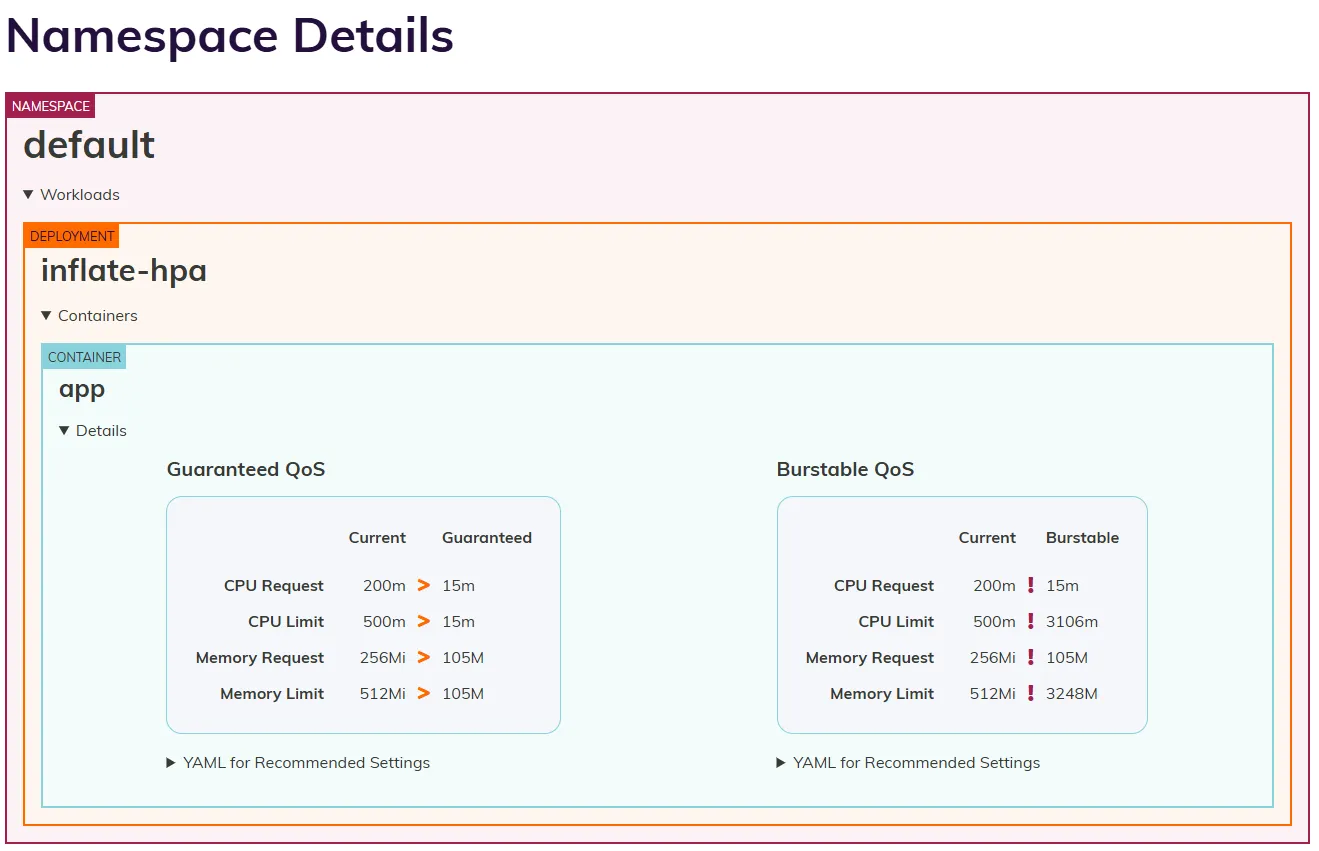
Comprendre les recommandations
Section intitulée « Comprendre les recommandations »Quand vous regardez une ligne du dashboard Goldilocks pour un workload, vous voyez trois informations :
- Les valeurs actuelles (ce que vous avez mis dans vos manifests)
- Une recommandation Guaranteed
- Une recommandation Burstable
Ces deux colonnes ne sont pas “bien vs mal” : ce sont deux stratégies différentes pour dimensionner vos pods. La suite de ce chapitre vous donne tout ce qu’il faut pour choisir en 2 minutes.
Requests vs limits : ce qui compte vraiment
Section intitulée « Requests vs limits : ce qui compte vraiment »Dans Kubernetes, chaque conteneur peut définir deux valeurs par ressource (CPU et mémoire) :
- requests : la réservation minimale. Kubernetes garantit que ces ressources seront disponibles pour votre conteneur. C’est comme réserver une table au restaurant — la place est à vous même si vous n’avez pas encore commandé.
- limits : le plafond maximal. Le conteneur ne pourra jamais dépasser cette valeur.
L’impact concret est différent selon la ressource :
| Ressource | Si le conteneur dépasse sa limit | Conséquence |
|---|---|---|
| Mémoire | Kubernetes tue le conteneur (OOMKilled) | Redémarrage du pod, potentielle indisponibilité |
| CPU | Kubernetes ralentit le conteneur (throttling) | Latence accrue, timeouts possibles, mais pas de crash |
QoS Kubernetes : pourquoi Goldilocks propose 2 colonnes
Section intitulée « QoS Kubernetes : pourquoi Goldilocks propose 2 colonnes »La relation entre requests et limits détermine la classe QoS (Quality of Service) du pod. Cette classe influence qui se fait évincer en premier quand un nœud manque de mémoire :
| Classe QoS | Condition | Protection |
|---|---|---|
| Guaranteed | requests = limits (CPU et mémoire) | Le plus protégé — évincé en dernier recours |
| Burstable | requests < limits (au moins une ressource) | Protection moyenne — peut être évincé sous pression |
| BestEffort | Pas de requests ni limits | Aucune protection — évincé en premier |
Goldilocks vous propose donc :
- Une recommandation qui force votre pod en Guaranteed (requests = limits)
- Une recommandation qui garde votre pod en Burstable (requests < limits)
Guaranteed : stabilité maximale
Section intitulée « Guaranteed : stabilité maximale »Dans la colonne Guaranteed, Goldilocks propose des requests égales aux
limits. Les deux valeurs sont identiques, calculées à partir de la
recommandation target du VPA (la consommation “normale” observée).
# Ce que Goldilocks recommande en Guaranteedresources: requests: cpu: "100m" # ← identique à limits memory: "256Mi" # ← identique à limits limits: cpu: "100m" # ← identique à requests memory: "256Mi" # ← identique à requestsCe que ça signifie : votre pod dispose toujours d’exactement 100m de CPU et 256Mi de mémoire. Pas plus, pas moins. Il ne peut pas “burster” au-delà, mais il sera le dernier évincé en cas de pression sur le nœud.
Ce qu’il faut savoir : vous empêchez le “burst”. Si vous sous-estimez les besoins, le CPU sera throttled et la mémoire risque un OOMKilled. C’est pourquoi il faut attendre que les recommandations soient stables avant de les appliquer.
Burstable : optimisation et flexibilité
Section intitulée « Burstable : optimisation et flexibilité »Dans la colonne Burstable, Goldilocks propose des requests inférieures
aux limits. Les requests viennent du lowerBound du VPA (consommation
minimale observée), les limits viennent du upperBound (pics observés).
# Ce que Goldilocks recommande en Burstableresources: requests: cpu: "50m" # ← minimum "raisonnable" (lowerBound) memory: "128Mi" # ← minimum "raisonnable" (lowerBound) limits: cpu: "500m" # ← pire cas observé (upperBound) memory: "512Mi" # ← pire cas observé (upperBound)Ce que ça signifie : votre pod a 50m de CPU garantis, mais peut grimper jusqu’à 500m lors d’un pic. C’est plus économique (vous ne réservez que 50m au lieu de 500m pour le scheduler), mais le pod est moins protégé en cas de pression mémoire sur le nœud.
Ce qu’il faut savoir : le pod est plus sensible à la pression mémoire du
nœud (évictions possibles). Il faut bien dimensionner la limit mémoire
(alignée sur upperBound) pour éviter les OOMKilled.
Quel choix pour quel workload ?
Section intitulée « Quel choix pour quel workload ? »Voici une règle de base pour choisir entre Guaranteed et Burstable selon le type de workload :
| Type de workload | Recommandation | Pourquoi |
|---|---|---|
| Base de données (PostgreSQL, MySQL) | Guaranteed | Éviction = perte de connexions, corruption possible |
| Cache (Redis, Memcached) | Guaranteed | Performances constantes requises |
| Broker (RabbitMQ, Kafka) | Guaranteed | Messages en transit perdus si éviction |
| API / Backend web | Burstable | Trafic variable, facile à redémarrer |
| Frontend / Nginx | Burstable | Stateless, pics possibles |
| Worker / Job batch | Burstable | Consommation ponctuelle élevée |
| CronJob | Burstable | Court, éphémère |
Méthode de choix en 4 questions
Section intitulée « Méthode de choix en 4 questions »Si le tableau ci-dessus ne couvre pas votre cas, posez-vous ces questions dans l’ordre :
-
Une indisponibilité de 30 à 60 secondes est-elle acceptable ?
Non → Guaranteed. Oui → passez à la question suivante.
-
Le service a-t-il des pics de consommation importants ?
Oui → Burstable. Non → passez à la question suivante.
-
Vous cherchez à optimiser les coûts ou la capacité du cluster ?
Oui → Burstable. Non → Guaranteed.
-
Vous avez déjà eu des OOMKilled ou des évictions sur ce service ?
Oui → commencez en Guaranteed (ou augmentez la limit mémoire). Non → Burstable est souvent un bon choix par défaut.
Les valeurs VPA derrière le dashboard
Section intitulée « Les valeurs VPA derrière le dashboard »Derrière les colonnes Guaranteed et Burstable, le VPA calcule 4 valeurs pour chaque conteneur. Voici ce qu’elles signifient :
- lowerBound : le minimum en dessous duquel l’application sera en difficulté (consommation “au repos”)
- target : la valeur recommandée pour un fonctionnement normal (consommation “moyenne”)
- upperBound : la valeur haute incluant les pics observés (consommation “jour de pointe”)
- uncappedTarget : le target théorique sans tenir compte des contraintes min/max — rarement utile au quotidien
Goldilocks fait ce mapping :
| Colonne dashboard | requests | limits |
|---|---|---|
| Guaranteed | target | target |
| Burstable | lowerBound | upperBound |
Pour voir les valeurs brutes sur un de vos workloads :
kubectl -n mon-namespace get vpa goldilocks-nginx \ -o jsonpath='{.status.recommendation.containerRecommendations[0]}' \ | python3 -m json.toolExemple de sortie :
{ "containerName": "nginx", "lowerBound": { "cpu": "15m", "memory": "100Mi" }, "target": { "cpu": "50m", "memory": "256Mi" }, "upperBound": { "cpu": "500m", "memory": "512Mi" }, "uncappedTarget": { "cpu": "50m", "memory": "256Mi" }}Les erreurs à éviter
Section intitulée « Les erreurs à éviter »Avant d’appliquer les recommandations, gardez ces pièges en tête :
1. Copier-coller sans réfléchir — Les valeurs sont un point de départ, pas une vérité absolue. Si votre workload vient d’être déployé, les recommandations sont instables. Appliquez progressivement et mesurez l’impact.
2. Mettre une limit mémoire trop basse — C’est l’erreur la plus coûteuse.
Si vous choisissez Burstable, gardez une limit mémoire confortable (alignée
sur upperBound). Un OOMKilled en production est bien plus grave qu’un peu de
mémoire “réservée pour rien”.
3. Se fier aux chiffres trop tôt — Les premières heures donnent des tendances, pas des certitudes. Le VPA a besoin d’environ 8 jours pour des recommandations fiables. La première semaine, considérez les chiffres comme préliminaires.
4. Confondre requests et consommation réelle — Un pod peut consommer bien moins que ses requests. Les requests sont une réservation pour le scheduler, pas une mesure de ce que le pod utilise réellement. C’est pourquoi Burstable aide à ne pas “bloquer” le scheduler inutilement.
En résumé
Section intitulée « En résumé »- Guaranteed = vous payez la stabilité (moins de surprises, moins de flexibilité)
- Burstable = vous payez l’efficacité (meilleur usage du cluster, mais compromis sur la protection)
Configuration avancée
Section intitulée « Configuration avancée »Goldilocks offre plusieurs options pour personnaliser son comportement selon vos besoins.
Activer tous les namespaces par défaut
Section intitulée « Activer tous les namespaces par défaut »Au lieu de labelliser chaque namespace, vous pouvez inverser le comportement :
helm upgrade goldilocks fairwinds-stable/goldilocks \ --namespace goldilocks \ --set controller.flags.on-by-default=true \ --set controller.flags.exclude-namespaces="kube-system,kube-public,goldilocks"Avec cette configuration, tous les namespaces sont surveillés sauf ceux explicitement exclus.
Mode de mise à jour automatique
Section intitulée « Mode de mise à jour automatique »Par défaut, les VPA créés sont en mode Off (recommandation uniquement). Pour
activer la mise à jour automatique des requests sur un namespace :
kubectl label namespace mon-namespace goldilocks.fairwinds.com/vpa-update-mode=autoVous pouvez aussi cibler un workload spécifique via une annotation :
kubectl annotate deployment mon-deployment \ goldilocks.fairwinds.com/vpa-update-mode=autoLes modes disponibles sont :
| Mode | Comportement |
|---|---|
Off | Recommandation uniquement (défaut) |
Initial | Applique les recommandations uniquement à la création du pod (via l’Admission Controller) |
Auto | Applique les recommandations à la création et évicte les pods existants pour les recréer avec les nouvelles valeurs (requiert le VPA Updater) |
Activer le VPA Updater
Section intitulée « Activer le VPA Updater »Pour que le mode Auto fonctionne complètement, activez L’Updater :
helm upgrade goldilocks fairwinds-stable/goldilocks \ --namespace goldilocks \ --reuse-values \ --set vpa.updater.enabled=true \ --set vpa.updater.image.repository=10.100.4.10/autoscaling/vpa-updater \ --set vpa.updater.image.tag=1.4.1Le piège du min-replicas
Section intitulée « Le piège du min-replicas »Par défaut, le VPA Updater refuse d’évictera un pod si le Deployment a moins de 2 replicas (sécurité). Vous verrez ce message dans les logs du updater :
"Too few replicas" livePods=1 requiredPods=2 globalMinReplicas=2Pour autoriser l’éviction sur des Deployments single-replica :
helm upgrade goldilocks fairwinds-stable/goldilocks \ --namespace goldilocks \ --reuse-values \ --set vpa.updater.extraArgs.min-replicas=1Comment l’Updater décide d’évicter un pod
Section intitulée « Comment l’Updater décide d’évicter un pod »L’Updater ne force pas l’éviction dès que les ressources diffèrent du
target. Il n’évicte que si les ressources actuelles sortent de la plage
[lowerBound, upperBound]. Exemple :
| CPU | Mémoire | |
|---|---|---|
| lowerBound | 15m | 100Mi |
| target | 15m | 100Mi |
| upperBound | 767m | 765Mi |
| Actuel | 200m | 256Mi |
Ici, 200m est entre 15m et 767m → l’Updater considère que les ressources sont
“dans la plage” et ne fait rien. Pour forcer l’application immédiate du
target, faites un rollout restart — l’Admission Controller injectera les
valeurs cibles lors de la recréation :
kubectl rollout restart deployment/mon-deploymentExclure certains conteneurs
Section intitulée « Exclure certains conteneurs »Les sidecars comme Istio ou Linkerd peuvent fausser les recommandations. Pour les exclure :
kubectl label deployment mon-deployment \ goldilocks.fairwinds.com/exclude-containers=istio-proxy,linkerd-proxyVous pouvez aussi les exclure globalement via les options du dashboard :
helm upgrade goldilocks fairwinds-stable/goldilocks \ --namespace goldilocks \ --set dashboard.flags.exclude-containers="istio-proxy,linkerd-proxy"Ignorer certains types de workloads
Section intitulée « Ignorer certains types de workloads »Pour ne pas créer de VPA pour les Jobs et CronJobs (qui sont éphémères) :
helm upgrade goldilocks fairwinds-stable/goldilocks \ --namespace goldilocks \ --set controller.flags.ignore-controller-kind="Job,CronJob"Resource Policy personnalisée
Section intitulée « Resource Policy personnalisée »Vous pouvez définir des limites min/max pour les recommandations via une annotation sur le namespace :
apiVersion: v1kind: Namespacemetadata: name: production labels: goldilocks.fairwinds.com/enabled: "true" annotations: goldilocks.fairwinds.com/vpa-resource-policy: | { "containerPolicies": [ { "containerName": "app", "minAllowed": {"cpu": "100m", "memory": "128Mi"}, "maxAllowed": {"cpu": "2", "memory": "4Gi"} } ] }Cette configuration empêche les recommandations de descendre en dessous de 100m CPU / 128Mi ou de dépasser 2 CPU / 4Gi.
Utilisation en ligne de commande
Section intitulée « Utilisation en ligne de commande »Bien que le dashboard soit la méthode principale, Goldilocks fournit aussi une CLI pour l’automatisation.
Générer un résumé JSON
Section intitulée « Générer un résumé JSON »Pour exporter toutes les recommandations en JSON (utile pour l’intégration CI/CD) :
# Via kubectl exec dans le pod controllerkubectl -n goldilocks exec -it deployment/goldilocks-controller -- goldilocks summaryOu avec le binaire local :
goldilocks summaryLa sortie JSON peut être parsée pour générer des alertes ou des rapports automatisés.
Créer des VPA manuellement
Section intitulée « Créer des VPA manuellement »Pour créer des VPA dans un namespace spécifique sans utiliser le controller :
goldilocks create-vpas -n mon-namespaceCette commande est utile pour tester Goldilocks sans installer le controller.
Dépannage
Section intitulée « Dépannage »Problèmes courants et solutions
Section intitulée « Problèmes courants et solutions »| Problème | Cause probable | Solution |
|---|---|---|
| Pas de VPA créés | Namespace non labellisé | kubectl label ns mon-namespace goldilocks.fairwinds.com/enabled=true |
| Pas de recommandations | metrics-server non fonctionnel | Vérifier kubectl get apiservice v1beta1.metrics.k8s.io |
| Recommandations “100T” ou incohérentes | VPA n’a pas assez de données | Attendre quelques jours (8 jours pour une précision optimale) |
| Dashboard inaccessible | Service pas exposé | kubectl -n goldilocks port-forward svc/goldilocks-dashboard 8080:80 |
| Erreur “VPA CRD not found” | VPA non installé | Installer avec helm upgrade --set vpa.enabled=true |
Vérifier les logs
Section intitulée « Vérifier les logs »Pour diagnostiquer un problème avec le controller :
kubectl -n goldilocks logs deployment/goldilocks-controllerPour le VPA Recommender :
kubectl -n goldilocks logs deployment/goldilocks-vpa-recommenderVérifier que metrics-server fonctionne
Section intitulée « Vérifier que metrics-server fonctionne »kubectl top pods -n mon-namespaceSi cette commande échoue avec “Metrics API not available”, corrigez metrics-server avant de continuer.
Bonnes pratiques
Section intitulée « Bonnes pratiques »Workflow recommandé
Section intitulée « Workflow recommandé »-
Déployez sans ressources spécifiques (ou avec des estimations larges)
Laissez votre application tourner quelques jours pour collecter des métriques représentatives.
-
Activez Goldilocks sur le namespace
Fenêtre de terminal kubectl label ns mon-namespace goldilocks.fairwinds.com/enabled=true -
Attendez 1 à 2 semaines
Les recommandations s’affinent avec le temps. Les premières valeurs peuvent être imprécises.
-
Consultez le dashboard et appliquez les recommandations
Choisissez Guaranteed ou Burstable selon vos besoins, puis mettez à jour vos manifests.
-
Réitérez après chaque changement majeur
Une nouvelle version de l’application peut avoir une consommation différente.
Ce qu’il faut éviter
Section intitulée « Ce qu’il faut éviter »- Copier aveuglément les recommandations : elles sont un point de départ, pas une vérité absolue
- Activer le mode Auto sans l’Updater : le label
vpa-update-mode=autoseul ne suffit pas, il faut aussivpa.updater.enabled=true - Utiliser Auto avec min-replicas=1 en production sans PodDisruptionBudget : risque d’indisponibilité
- Ignorer les pics de charge : les recommandations Burstable tiennent compte des pics, utilisez-les pour les workloads variables
- Oublier de réajuster : les besoins évoluent, vérifiez les recommandations régulièrement
À retenir
Section intitulée « À retenir »- Goldilocks analyse la consommation réelle de vos pods et génère des recommandations objectives
- Version actuelle : v4.14.1 (chart 10.2.0, février 2026), basé sur le Vertical Pod Autoscaler 1.4.1
- Installation :
helm install goldilocks fairwinds-stable/goldilocks --set vpa.enabled=true - Activation :
kubectl label ns mon-namespace goldilocks.fairwinds.com/enabled=true - Deux types de recommandations : Guaranteed (stable) et Burstable (pics)
- Le VPA a besoin de 8 jours minimum pour des recommandations précises
- Le mode Auto nécessite le VPA Updater (
vpa.updater.enabled=true) — sans lui, seulInitialfonctionne - L’Updater respecte
min-replicas=2par défaut — configurermin-replicas=1si vos Deployments ont un seul replica - L’Updater n’évicte que si les ressources sortent de la plage
[lowerBound, upperBound]— utilisezrollout restartpour forcer - Le dashboard Goldilocks n’a pas d’authentification — sécurisez l’accès
Prochaines étapes
Section intitulée « Prochaines étapes »Ressources
Section intitulée « Ressources »- Documentation officielle : goldilocks.docs.fairwinds.com
- Repository GitHub : github.com/FairwindsOps/goldilocks
- VPA documentation : github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler
- Chart Helm : github.com/FairwindsOps/charts/tree/master/stable/goldilocks