Karpenter fonctionne sur AWS, mais rien ne vous empêche de l’adapter à votre cloud. Ce guide documente le développement complet d’un provider Karpenter pour Outscale avec Talos Linux — de l’interface CloudProvider aux bugs qui suppriment tous vos nœuds en 30 secondes.
Ce que vous allez apprendre :
Section intitulée « Ce que vous allez apprendre : »- Implémenter les 9 méthodes de l’interface CloudProvider (Create, Delete, List, Get…)
- Éviter les bugs critiques : GC destructeur, tags manquants, signaux D-Bus
- Debugger efficacement avec osc-cli quand les nodes disparaissent
- Tester votre provider avec un cycle build/deploy rapide
Avant de commencer : pourquoi c’est difficile
Section intitulée « Avant de commencer : pourquoi c’est difficile »Développer un provider Karpenter, c’est faire fonctionner 6 composants ensemble. Chacun a ses propres attentes, et si l’un d’eux reçoit des données incorrectes, le système entier peut s’effondrer.
Voici les acteurs en jeu :
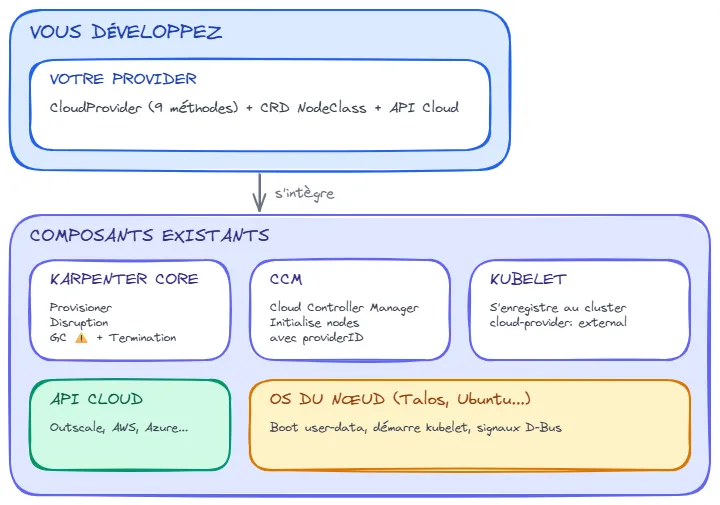
Étape 1 : Comprendre le flux de provisionnement
Section intitulée « Étape 1 : Comprendre le flux de provisionnement »Avant d’écrire du code, comprenez ce qui se passe quand un pod est en Pending :
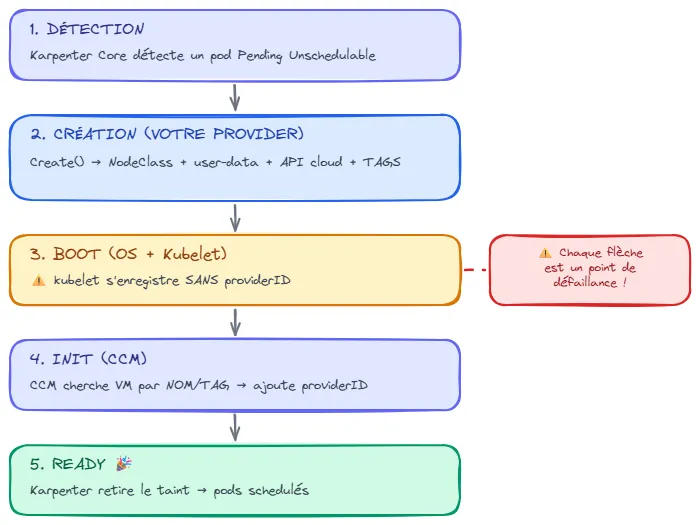
Chaque flèche est un point de défaillance. C’est pourquoi il faut comprendre ce flux avant de coder.
Étape 2 : Préparer votre environnement
Section intitulée « Étape 2 : Préparer votre environnement »Ce dont vous avez besoin
Section intitulée « Ce dont vous avez besoin »# Go 1.25+ (Karpenter v1.9 l'exige)go version# go1.25.7 linux/amd64
# Docker pour builder les imagesdocker --version
# kubectl configuré sur un cluster de testkubectl cluster-info
# CLI de votre cloud pour debugger les VMs# AWS : aws-cli, GCP : gcloud, Azure : az, Outscale : osc-cliL’outil de debug indispensable : le CLI de votre cloud
Section intitulée « L’outil de debug indispensable : le CLI de votre cloud »Quand quelque chose ne fonctionne pas, vous devez inspecter vos VMs directement dans le cloud. Voici les opérations essentielles (adaptez à votre CLI) :
# Lister toutes les VMs gérées par Karpenter# Filtrer par le tag "karpenter.sh/managed-by"<cloud-cli> describe-instances --filters "tag:karpenter.sh/managed-by=<cluster>"
# Voir les tags d'une VM spécifique<cloud-cli> describe-instances --instance-id <vm-id> | jq '.Tags'
# Vérifier l'état d'une VM<cloud-cli> describe-instances --instance-id <vm-id> | jq '{Id, State, PrivateIp}'
# Lire les logs de console (boot de l'OS)<cloud-cli> get-console-output --instance-id <vm-id> | base64 -d | tail -50Étape 3 : Structure de votre projet
Section intitulée « Étape 3 : Structure de votre projet »Voici l’organisation recommandée :
karpenter-provider-<cloud>/│├── cmd/controller/main.go ← Point d'entrée│├── pkg/│ ├── apis/v1alpha1/ ← Votre CRD NodeClass│ │ ├── <cloud>nodeclass_types.go│ │ ├── register.go│ │ └── hash.go ← Pour drift detection│ ││ ├── cloudprovider/ ← L'interface CloudProvider│ │ └── cloudprovider.go ← Create, Delete, List, Get...│ ││ ├── vm/ ← Wrapper API cloud│ │ └── vm.go ← Appels API avec retry│ ││ ├── instancetype/ ← Catalogue des types d'instances│ │ └── instancetypes.go│ ││ └── utils/ ← Helpers (providerID, hostname)│ └── utils.go│├── charts/ ← Helm chart pour déploiement│ └── karpenter-provider-<cloud>/│├── Dockerfile└── go.modLes dépendances Go essentielles
Section intitulée « Les dépendances Go essentielles »module github.com/<org>/karpenter-provider-<cloud>
go 1.25.7
require ( // Karpenter Core - L'INTERFACE que vous implémentez sigs.k8s.io/karpenter v1.9.1
// Controller-runtime - Pour créer des controllers K8s sigs.k8s.io/controller-runtime v0.22.4
// SDK de votre cloud (remplacer par le SDK approprié) // github.com/<cloud-provider>/<sdk> vX.Y.Z
// Kubernetes API k8s.io/api v0.35.0 k8s.io/apimachinery v0.35.0 k8s.io/client-go v0.35.0)Étape 4 : Définir votre CRD NodeClass
Section intitulée « Étape 4 : Définir votre CRD NodeClass »La NodeClass contient la configuration spécifique à votre cloud. Les utilisateurs la créent pour dire “voici comment créer mes nœuds”.
Pourquoi c’est important
Section intitulée « Pourquoi c’est important »Sans NodeClass, Karpenter ne sait pas :
- Quelle image utiliser (AMI/OMI)
- Dans quel subnet créer la VM
- Quels security groups attacher
- Comment initialiser l’OS (user-data)
Exemple : votre NodeClass
Section intitulée « Exemple : votre NodeClass »// pkg/apis/v1alpha1/<cloud>nodeclass_types.go
type <Cloud>NodeClassSpec struct { // Où créer les VMs SubnetIDs []string `json:"subnetIds"` SecurityGroupIDs []string `json:"securityGroupIds"`
// Quelle image utiliser ImageID string `json:"imageId"` // OMI Talos
// Pour SSH debug (optionnel) KeypairName string `json:"keypairName,omitempty"`
// Tags additionnels Tags map[string]string `json:"tags,omitempty"`
// Config disques BlockDeviceMappings []BlockDeviceMapping `json:"blockDeviceMappings,omitempty"`
// Config spécifique Talos Talos TalosConfig `json:"talos"`}Comment les utilisateurs l’utilisent
Section intitulée « Comment les utilisateurs l’utilisent »apiVersion: karpenter.<cloud>.com/v1alpha1kind: <Cloud>NodeClassmetadata: name: defaultspec: imageId: "ami-xxxx" # Image de votre OS (Talos, Bottlerocket...) subnetIds: - "subnet-aaa" # Zone A - "subnet-bbb" # Zone B securityGroupIds: - "sg-xxxx" keypairName: "my-keypair" # Optionnel, pour debug SSH tags: Cluster: "prod" Environment: "production"Étape 5 : Implémenter l’interface CloudProvider
Section intitulée « Étape 5 : Implémenter l’interface CloudProvider »C’est le cœur de votre provider. Voici les 9 méthodes à implémenter :
Vue d’ensemble
Section intitulée « Vue d’ensemble »| Méthode | Appelée par | Ce qu’elle fait | Criticité |
|---|---|---|---|
Create() | Provisioner | Crée une VM | Haute |
Delete() | Termination | Supprime une VM | Haute |
Get() | Plusieurs | Récupère l’état d’une VM | Moyenne |
List() | GC Controller | Liste TOUTES les VMs gérées | CRITIQUE |
GetInstanceTypes() | Provisioner | Catalogue des types | Moyenne |
IsDrifted() | Disruption | Détecte les changements de config | Moyenne |
Name() | Core | Retourne “<cloud>“ | Faible |
GetSupportedNodeClasses() | Core | Retourne vos CRDs | Faible |
RepairPolicies() | Core | Règles de réparation | Faible |
La règle d’or : les TAGS
Section intitulée « La règle d’or : les TAGS »Les tags sont critiques. Ils permettent à différents composants de retrouver vos VMs.
| Tag | Valeur | Utilisé par | Si absent… |
|---|---|---|---|
karpenter.sh/managed-by | <cluster-name> | GC (List()) | Tous les nodes sont supprimés en 30s |
<cloud>/node-name | <hostname> | CCM de votre cloud | Node reste Initialized=Unknown |
karpenter.sh/nodeclaim | <nodeclaim-name> | Traçabilité | Debug difficile |
karpenter.sh/nodepool | <nodepool-name> | Traçabilité | Debug difficile |
Implémenter Create() étape par étape
Section intitulée « Implémenter Create() étape par étape »func (c *CloudProvider) Create(ctx context.Context, nodeClaim *karpv1.NodeClaim) (*karpv1.NodeClaim, error) { logger := log.FromContext(ctx)
// ═══════════════════════════════════════════════════════════════ // ÉTAPE 1 : Récupérer la NodeClass // ═══════════════════════════════════════════════════════════════ // La NodeClass contient la config cloud (image, subnet, etc.)
nodeClass, err := c.getNodeClass(ctx, nodeClaim) if err != nil { return nil, fmt.Errorf("failed to get node class: %w", err) }
logger.Info("NodeClass loaded", "imageId", nodeClass.Spec.ImageID, "subnets", nodeClass.Spec.SubnetIDs, )
// ═══════════════════════════════════════════════════════════════ // ÉTAPE 2 : Choisir le type d'instance // ═══════════════════════════════════════════════════════════════ // Basé sur les requirements du NodeClaim (CPU, mémoire, GPU...)
instanceType := c.selectInstanceType(nodeClaim) logger.Info("Instance type selected", "type", instanceType)
// ═══════════════════════════════════════════════════════════════ // ÉTAPE 3 : Générer le user-data // ═══════════════════════════════════════════════════════════════ // C'est la config d'initialisation du nœud (Talos machine config)
userData, err := c.generateUserData(ctx, nodeClass, nodeClaim) if err != nil { return nil, fmt.Errorf("failed to generate user-data: %w", err) }
// ═══════════════════════════════════════════════════════════════ // ÉTAPE 4 : Construire les TAGS (CRITIQUE !) // ═══════════════════════════════════════════════════════════════
tags := map[string]string{ // ⚠️ OBLIGATOIRE : Le GC utilise ce tag pour List() "karpenter.sh/managed-by": c.clusterName,
// Traçabilité "karpenter.sh/nodeclaim": nodeClaim.Name, "karpenter.sh/nodepool": nodeClaim.Labels["karpenter.sh/nodepool"],
// Standard K8s "kubernetes.io/cluster/" + c.clusterName: "owned", } // Copier les tags de la NodeClass for k, v := range nodeClass.Spec.Tags { tags[k] = v }
// ═══════════════════════════════════════════════════════════════ // ÉTAPE 5 : Créer la VM via l'API cloud // ═══════════════════════════════════════════════════════════════
vmOutput, err := c.vmService.Create(ctx, &vm.CreateInput{ InstanceType: instanceType, ImageID: nodeClass.Spec.ImageID, SubnetID: c.selectSubnet(nodeClass, nodeClaim), SecurityGroupIDs: nodeClass.Spec.SecurityGroupIDs, KeypairName: nodeClass.Spec.KeypairName, UserData: userData, Tags: tags, }) if err != nil { logger.Error(err, "VM creation failed") return nil, fmt.Errorf("failed to create VM: %w", err) }
logger.Info("VM created", "vmID", vmOutput.VMID, "privateIP", vmOutput.PrivateIP, "zone", vmOutput.Zone, )
// ═══════════════════════════════════════════════════════════════ // ÉTAPE 6 : Ajouter le tag pour le CCM // ═══════════════════════════════════════════════════════════════ // Le CCM de votre cloud a besoin d'un tag pour retrouver la VM // Consultez la doc de votre CCM pour savoir quel tag utiliser
hostname := utils.IPToHostname(vmOutput.PrivateIP) // "ip-10-0-1-88"
err = c.vmService.UpdateTags(ctx, vmOutput.VMID, map[string]string{ "Name": fmt.Sprintf("%s-%s", c.clusterName, hostname), "<cloud>/node-name": hostname, // ⚠️ Tag attendu par votre CCM }) if err != nil { // Log mais continue - le node sera quand même créé logger.Error(err, "Failed to update tags (non-fatal)") }
// ═══════════════════════════════════════════════════════════════ // ÉTAPE 7 : Hydrater le NodeClaim avec les infos // ═══════════════════════════════════════════════════════════════
// Provider ID (format attendu par le CCM) nodeClaim.Status.ProviderID = fmt.Sprintf("aws:///%s/%s", vmOutput.Zone, vmOutput.VMID) nodeClaim.Status.NodeName = hostname
// Labels obligatoires pour Karpenter nodeClaim.Labels[v1.LabelInstanceTypeStable] = instanceType nodeClaim.Labels[v1.LabelTopologyZone] = vmOutput.Zone nodeClaim.Labels[karpv1.CapacityTypeLabelKey] = karpv1.CapacityTypeOnDemand
// Capacity nodeClaim.Status.Capacity = v1.ResourceList{ v1.ResourceCPU: resource.MustParse("4"), v1.ResourceMemory: resource.MustParse("16Gi"), v1.ResourcePods: resource.MustParse("110"), }
logger.Info("NodeClaim hydrated successfully", "nodeClaim", nodeClaim.Name, "providerID", nodeClaim.Status.ProviderID, "nodeName", nodeClaim.Status.NodeName, )
return nodeClaim, nil}Implémenter List() — LE PLUS CRITIQUE
Section intitulée « Implémenter List() — LE PLUS CRITIQUE »List() est appelé par le GC Controller toutes les 30 secondes. Il doit retourner toutes les VMs gérées par Karpenter.
func (c *CloudProvider) List(ctx context.Context) ([]*karpv1.NodeClaim, error) { logger := log.FromContext(ctx)
// ═══════════════════════════════════════════════════════════════ // FILTRER PAR LE TAG karpenter.sh/managed-by // ═══════════════════════════════════════════════════════════════ // C'est le SEUL moyen pour le GC de savoir quelles VMs sont gérées
vms, err := c.vmService.List(ctx, map[string]string{ "karpenter.sh/managed-by": c.clusterName, // ⚠️ DOIT correspondre au tag dans Create() })
// ═══════════════════════════════════════════════════════════════ // ⚠️ ATTENTION : NE JAMAIS RETOURNER UNE LISTE VIDE EN CAS D'ERREUR // ═══════════════════════════════════════════════════════════════ // Si vous retournez (nil, nil) ou ([]NodeClaim{}, nil), le GC // pensera qu'il n'y a aucune VM → il supprimera TOUS les NodeClaims
if err != nil { logger.Error(err, "Failed to list VMs - returning error to prevent GC disaster") return nil, fmt.Errorf("failed to list VMs: %w", err) // ← RETOURNER L'ERREUR }
// Convertir en NodeClaims var nodeClaims []*karpv1.NodeClaim for _, vmInfo := range vms { providerID := fmt.Sprintf("aws:///%s/%s", vmInfo.Zone, vmInfo.VMID) nodeClaims = append(nodeClaims, &karpv1.NodeClaim{ Status: karpv1.NodeClaimStatus{ ProviderID: providerID, NodeName: utils.IPToHostname(vmInfo.PrivateIP), }, }) }
logger.V(1).Info("Listed VMs", "count", len(nodeClaims)) return nodeClaims, nil}Implémenter Delete()
Section intitulée « Implémenter Delete() »func (c *CloudProvider) Delete(ctx context.Context, nodeClaim *karpv1.NodeClaim) error { logger := log.FromContext(ctx)
if nodeClaim.Status.ProviderID == "" { // Pas de providerID = la VM n'a jamais été créée return cloudprovider.NewNodeClaimNotFoundError( fmt.Errorf("NodeClaim has no provider ID"), ) }
_, vmID, err := utils.ParseProviderID(nodeClaim.Status.ProviderID) if err != nil { return fmt.Errorf("failed to parse provider ID: %w", err) }
// Vérifier l'état de la VM vmInfo, err := c.vmService.Get(ctx, vmID) if err != nil { if vm.IsVMNotFound(err) { // VM déjà supprimée → OK, retourner NodeClaimNotFoundError // Cela permet à Karpenter de retirer les finalizers return cloudprovider.NewNodeClaimNotFoundError( fmt.Errorf("VM %s not found", vmID), ) } // Erreur transitoire → requeue return fmt.Errorf("failed to get VM state: %w", err) }
// VM en cours de suppression ou déjà supprimée if vmInfo.State == "terminated" || vmInfo.State == "shutting-down" { return cloudprovider.NewNodeClaimNotFoundError( fmt.Errorf("VM %s is %s", vmID, vmInfo.State), ) }
// Demander la suppression logger.Info("Deleting VM", "vmID", vmID) if err := c.vmService.Delete(ctx, vmID); err != nil { return fmt.Errorf("failed to delete VM: %w", err) }
// Retourner nil = Karpenter va re-appeler Delete() jusqu'à ce que // la VM soit vraiment terminée (et qu'on retourne NodeClaimNotFoundError) return nil}Étape 6 : Gérer les appels API avec retry
Section intitulée « Étape 6 : Gérer les appels API avec retry »L’API Outscale (comme toute API cloud) peut échouer transitoirement. Sans retry, une erreur 500 peut déclencher le GC.
Wrapper API avec retry et backoff
Section intitulée « Wrapper API avec retry et backoff »func (s *Service) List(ctx context.Context, tags map[string]string) ([]VMInfo, error) { var lastErr error
// 3 tentatives avec backoff exponentiel for attempt := 0; attempt < 3; attempt++ { vms, err := s.listVMsInternal(ctx, tags) if err == nil { return vms, nil }
lastErr = err backoff := time.Duration(1<<attempt) * time.Second // 1s, 2s, 4s log.FromContext(ctx).Error(err, "API call failed, retrying", "attempt", attempt+1, "backoff", backoff, ) time.Sleep(backoff) }
return nil, fmt.Errorf("API failed after 3 attempts: %w", lastErr)}
func (s *Service) listVMsInternal(ctx context.Context, tags map[string]string) ([]VMInfo, error) { // Construire le filtre de tags au format Outscale // Format: "KEY=VALUE" var tagFilters []string for k, v := range tags { tagFilters = append(tagFilters, fmt.Sprintf("%s=%s", k, v)) }
req := osc.ReadVmsRequest{ Filters: &osc.FiltersVm{ Tags: &tagFilters, VmStateNames: &[]string{"pending", "running", "stopping", "stopped"}, // ⚠️ NE PAS inclure "terminated" sinon les VMs supprimées // apparaissent dans la liste }, }
resp, _, err := s.Client.VmApi.ReadVms(s.AuthCtx).ReadVmsRequest(req).Execute() if err != nil { return nil, fmt.Errorf("ReadVms failed: %w", err) }
// Convertir la réponse var vms []VMInfo for _, vm := range resp.GetVms() { vms = append(vms, VMInfo{ VMID: vm.GetVmId(), State: vm.GetState(), PrivateIP: vm.GetPrivateIp(), Zone: vm.GetPlacement().GetSubregionName(), ImageID: vm.GetImageId(), }) }
return vms, nil}Étape 7 : Le cycle de développement
Section intitulée « Étape 7 : Le cycle de développement »Compiler et déployer rapidement
Section intitulée « Compiler et déployer rapidement »#!/bin/bashVERSION="${1:-v0.2.63}"REGISTRY="10.100.4.10"
cd ~/talos-dev/karpenter-provider-outscale
# 1. Compilerecho "=== Go build ==="go build ./...if [ $? -ne 0 ]; then echo "❌ Build failed" exit 1fi
# 2. Docker buildecho "=== Docker build ==="docker build --no-cache -t karpenter-provider-outscale:${VERSION} .
# 3. Pushecho "=== Push to registry ==="docker tag karpenter-provider-outscale:${VERSION} ${REGISTRY}/karpenter/karpenter-provider-outscale:${VERSION}docker push ${REGISTRY}/karpenter/karpenter-provider-outscale:${VERSION}
# 4. Déployerecho "=== Deploy ==="kubectl set image deployment/karpenter-provider-outscale \ controller=${REGISTRY}/karpenter/karpenter-provider-outscale:${VERSION} \ -n karpenter-system
# 5. Attendreecho "=== Wait for rollout ==="kubectl rollout status deployment/karpenter-provider-outscale -n karpenter-system --timeout=120s
echo ""echo "✅ Done! Version ${VERSION} deployed."echo "Logs: kubectl logs -n karpenter-system deployment/karpenter-provider-outscale -f"Tester le provisionnement
Section intitulée « Tester le provisionnement »# 1. Créer un deployment de testkubectl apply -f - <<'EOF'apiVersion: apps/v1kind: Deploymentmetadata: name: inflatespec: replicas: 0 selector: matchLabels: app: inflate template: metadata: labels: app: inflate spec: containers: - name: inflate image: nginx:alpine resources: requests: cpu: 1 memory: 1GiEOF
# 2. Déclencher le scale-upkubectl scale deployment/inflate --replicas=3
# 3. Observer dans 2 terminaux# Terminal 1 : NodeClaimswatch -n2 'kubectl get nodeclaims -o wide'
# Terminal 2 : Logskubectl logs -n karpenter-system deployment/karpenter-provider-<cloud> -f | grep -E "Create|List|Delete"Timeline attendue
Section intitulée « Timeline attendue »| Temps | Ce qui se passe |
|---|---|
| T+0s | kubectl scale → pods Pending |
| T+2s | Karpenter détecte → appelle Create() |
| T+5s | VM en création dans le cloud |
| T+30-60s | VM running, kubelet démarre |
| T+60-90s | kubelet s’enregistre → Node apparaît (NotReady) |
| T+90-120s | CNI ready → Node Ready |
| T+120s+ | Taint retiré → pods schedulés |
Étape 8 : Debug quand ça ne marche pas
Section intitulée « Étape 8 : Debug quand ça ne marche pas »Voici les problèmes les plus fréquents et comment les diagnostiquer :
“Le NodeClaim reste Launched mais jamais Registered"
Section intitulée « “Le NodeClaim reste Launched mais jamais Registered" »# 1. Trouver le VM ID dans le NodeClaimkubectl get nodeclaim <name> -o jsonpath='{.status.providerID}'# <scheme>:///<zone>/<vm-id>
# 2. Vérifier que la VM existe dans votre cloud<cloud-cli> describe-instances --instance-id <vm-id> | jq '.State'# "running" → OK, la VM existe
# 3. Vérifier les tags<cloud-cli> describe-instances --instance-id <vm-id> | jq '.Tags'# Chercher karpenter.sh/managed-by et le tag attendu par votre CCM
# 4. Lire les logs de boot<cloud-cli> get-console-output --instance-id <vm-id> | base64 -d | grep -E "kubelet|error|fail" | tail -30"Les nodes sont créés puis supprimés après 30s”
Section intitulée « "Les nodes sont créés puis supprimés après 30s” »C’est le bug GC.
# 1. Vérifier que List() retourne les VMskubectl logs -n karpenter-system deployment/karpenter-provider-<cloud> \ | grep "Listed VMs" | tail -5# Chercher "count": X — si X=0, le tag est manquant
# 2. Vérifier les tags dans le cloud<cloud-cli> describe-instances --filters "tag-key=karpenter.sh/managed-by"# Si vide → les tags ne sont pas ajoutés dans Create()
# 3. Vérifier la valeur du tag# La valeur doit correspondre EXACTEMENT au clusterName de votre provider”Le node reste Initialized=Unknown”
Section intitulée « ”Le node reste Initialized=Unknown” »Le CCM ne trouve pas la VM.
# 1. Logs du CCMkubectl logs -n kube-system -l app=<cloud>-cloud-controller-manager | grep "not found"
# 2. Vérifier le tag attendu par le CCM# Consultez la doc de votre CCM pour savoir quel tag il attend
# 3. Le hostname doit correspondre au node namekubectl get nodes -o jsonpath='{.items[*].metadata.name}'Retour d’expérience : ce que j’aurais aimé savoir
Section intitulée « Retour d’expérience : ce que j’aurais aimé savoir »Après plusieurs jours de développement sur ce provider, voici les leçons que j’en tire.
Le temps réel de développement
Section intitulée « Le temps réel de développement »J’avais estimé l’interface CloudProvider basique à une semaine. Il m’en a fallu deux — les edge cases de List() et Delete() m’ont piégé plusieurs fois.
L’intégration avec le CCM devait prendre 2 jours. Elle a pris 2 semaines. Le format du providerID, les tags attendus, la correspondance avec le hostname… chaque détail qui ne colle pas = un node qui ne s’initialise jamais.
Le plus long ? Le debug “nodes qui disparaissent”. Je n’avais rien prévu pour ça. Trois semaines à chercher qui supprimait mes nodes. J’ai dû forker trois projets (Karpenter, CCM, Talos) pour ajouter des logs à chaque point de décision shutdown/terminate.
La stabilisation production (retry, backoff, race conditions) : estimée à une semaine, réalisée en un mois.
Total : 4× plus long que prévu. Prévoyez large.
Ce qui m’a le plus surpris
Section intitulée « Ce qui m’a le plus surpris »- La documentation Karpenter est excellente… pour AWS. Pour un autre cloud, vous devez lire le code source du provider AWS ligne par ligne. J’ai passé des heures dans
github.com/aws/karpenter-provider-awspour comprendre les contrats implicites. - Le GC Controller est impitoyable. Il n’y a pas de “mode dégradé”. Si
List()retourne une erreur ou une liste vide, vos nodes sont supprimés. Point. C’est un choix de design volontaire (fail-fast), mais ça rend le debug très stressant. - Les logs par défaut sont insuffisants. Quand un node disparaît, vous voyez “NodeClaim deleted” dans les logs Karpenter. Mais vous ne savez pas si c’est le GC, la consolidation, le drift, ou une action manuelle. J’ai ajouté des logs customs à chaque point de décision.
Les compromis que j’ai faits
Section intitulée « Les compromis que j’ai faits »- Pas de spot instances : Mon cloud n’a pas d’équivalent. J’ai retiré toute la logique
CapacityTypeSpot. - Catalogue d’instances statique : Au lieu d’appeler l’API pour lister les types de VM disponibles, j’ai un fichier YAML statique. Plus simple, moins de maintenance.
- Pas de drift sur les security groups : Trop complexe à implémenter. Le drift ne détecte que les changements d’image.
Si c’était à refaire
Section intitulée « Si c’était à refaire »- Commencer par un provider en mode “dry-run”.
- Ajouter des logs dès le début : Pas après avoir perdu 3 jours sur un bug.
- Tester avec
consolidateAfter: Never: Désactiver la consolidation pendant le développement. - Un cluster de test dédié : J’ai cassé mon cluster de dev plusieurs fois.
Ressources
Section intitulée « Ressources »Karpenter
Section intitulée « Karpenter »- CloudProvider Interface — API Go v1.9 (l’interface à implémenter)
- Provider AWS — Implémentation de référence (à lire ligne par ligne)
- Karpenter Core — Code source des controllers
Documentation de votre cloud
Section intitulée « Documentation de votre cloud »Consultez la documentation API de votre cloud pour :
- Création de VMs : paramètres, tags, user-data
- Listing avec filtres : filtrage par tags pour
List() - Logs de console : pour debugger le boot de l’OS
- CCM : quel tag le Cloud Controller Manager attend
Karpenter
Section intitulée « Karpenter »- CloudProvider Interface — API Go v1.9
- Provider AWS — Implémentation de référence
- Karpenter Core — Code source des controllers