Vous gérez une infrastructure en production. Un jour, inévitablement, un incident survient : une base de données tombe, une API devient lente, un déploiement échoue. L’équipe résout le problème dans l’urgence. Et puis… rien. Pas de trace, pas d’analyse, pas de prévention.
Résultat : le même incident se reproduit 3 mois plus tard. Personne ne se souvient de la solution. On recommence à zéro.
Un postmortem SRE est un document d’analyse écrit après un incident de production. Il documente ce qui s’est passé, pourquoi, comment l’incident a été résolu, et surtout quelles actions concrètes éviteront que ça se reproduise. Cette pratique transforme les échecs en opportunités d’apprentissage collectif.
Dans ce guide, vous allez créer une collection Astro dédiée aux postmortems avec validation automatique des champs obligatoires, un template structuré selon les meilleures pratiques SRE (Google, Netflix), et un script interactif pour générer rapidement de nouveaux documents sans copier-coller.
Prérequis
Section intitulée « Prérequis »Avant de commencer, vous devez comprendre où se situent les postmortems dans l’écosystème de documentation opérationnelle :
Connaissances techniques requises :
- Notion de collections Astro (fichiers Markdown groupés avec validation)
- Bases de Zod (bibliothèque de validation TypeScript)
- JavaScript/Node.js pour comprendre le script de génération
- Familiarité avec le front-matter YAML (métadonnées en haut des fichiers Markdown)
Installation nécessaire :
- Projet Astro Starlight fonctionnel (voir les guides précédents)
- Node.js 20+ pour exécuter le script de génération
Pourquoi documenter les incidents ?
Section intitulée « Pourquoi documenter les incidents ? »La place du postmortem dans la documentation
Section intitulée « La place du postmortem dans la documentation »Selon les 5 familles de documentation opérationnelle, le postmortem appartient à la famille Historique. Cette famille conserve la mémoire des décisions et des événements pour éviter de répéter les erreurs.
Différence avec les autres familles :
| Type de doc | Question | Exemple | Quand l’écrire |
|---|---|---|---|
| Runbook (Procédures) | Comment agir ? | ”Redémarrer PostgreSQL en production” | Avant l’incident (procédure préventive) |
| Postmortem (Historique) | Que s’est-il passé ? Pourquoi ? | ”Panne PostgreSQL du 15 mai 2025” | Après l’incident (analyse) |
| ADR (Historique) | Pourquoi ce choix ? | ”Pourquoi PostgreSQL et pas MySQL” | Lors d’une décision d’architecture |
Le cycle vertueux : Le postmortem identifie souvent la nécessité de créer ou mettre à jour un runbook. Par exemple, après un incident “Saturation disque Kubernetes”, vous créerez un runbook “Nettoyer les images Docker inutilisées”.
Les bénéfices concrets
Section intitulée « Les bénéfices concrets »Les postmortems SRE remplissent plusieurs fonctions critiques :
- Apprentissage collectif : Partager les leçons apprises avec toute l’équipe (pas juste ceux qui ont géré l’incident)
- Culture blameless : Analyser les systèmes et processus défaillants, jamais blâmer les personnes
- Prévention : Identifier les actions correctives concrètes pour éviter la récurrence (avec responsables et dates)
- Transparence : Communiquer sur les incidents avec les parties prenantes (clients, management)
- Base de connaissances : Constituer un historique permettant de détecter les patterns (“3 incidents disque en 2 mois → problème systémique”)
- Amélioration des runbooks : Mettre à jour les procédures d’intervention quand elles s’avèrent incomplètes
Architecture de la solution
Section intitulée « Architecture de la solution »Qu’est-ce qu’une collection Astro ?
Section intitulée « Qu’est-ce qu’une collection Astro ? »Avant de commencer, clarifions ce concept clé.
Une collection Astro est un groupe de fichiers Markdown organisés dans un dossier, avec des règles de validation communes. Par exemple :
- Tous les fichiers dans
src/content/docs/postmortems/= collection “postmortems” - Règle commune : chaque postmortem DOIT avoir un champ
incident_date,severity,services_affected, etc. - Si vous oubliez un champ obligatoire → le build échoue avec une erreur claire
Analogie : Imaginez un formulaire web. Les champs requis (nom, email, etc.) sont validés avant soumission. Ici, c’est pareil : Astro valide chaque fichier avant de générer le site.
Pourquoi c’est utile pour les postmortems :
- ✅ Uniformité : Tous les postmortems ont la même structure (pas de champ manquant)
- ✅ Erreurs détectées tôt : Si vous oubliez
severity, le build vous le dit immédiatement - ✅ Exploitation des données : Vous pourrez filtrer par sévérité, calculer le MTTR moyen, etc.
- ✅ Documentation vivante : Le schéma sert de documentation sur les champs attendus
Ce que vous allez construire
Section intitulée « Ce que vous allez construire »Vous allez mettre en place :
- Un schéma Zod pour valider les métadonnées des postmortems (date d’incident obligatoire, sévérité limitée à 4 valeurs, etc.)
- Une collection Astro dédiée, étendue avec le schéma postmortem (réutilisant la collection “docs” existante)
- Un template structuré incluant toutes les sections SRE (chronologie, 5 Pourquoi, actions correctives, leçons apprises)
- Un script de génération interactif pour créer rapidement de nouveaux postmortems sans copier-coller
Répertoiresrc/
Répertoirecontent/
- config.ts Configuration des collections avec schéma postmortem
Répertoiredocs/
Répertoirepostmortems/ Collection dédiée aux postmortems
- 2025-05-15-panne-postgresql.md
- 2025-06-03-degradation-api.md
Répertoiresre/ Pages de référence (pas de collection)
- metriques-slo.md
- observabilite.md
- runbooks.md
Répertoirescripts/
- create-postmortem.js Script de génération interactive
Étendre le schéma de contenu
Section intitulée « Étendre le schéma de contenu »Comprendre les schémas Zod
Section intitulée « Comprendre les schémas Zod »Zod est une bibliothèque TypeScript qui permet de définir la structure attendue des données et de valider automatiquement que chaque fichier respecte cette structure.
Concrètement : Si vous définissez severity: z.enum(['critical', 'high', 'medium', 'low']), alors :
- ✅
severity: critical→ accepté - ✅
severity: high→ accepté - ❌
severity: critique→ ERREUR : “critique” n’est pas dans la liste autorisée - ❌ Absence de
severity→ ERREUR : champ obligatoire manquant
Pourquoi c’est important : Sans schéma, chacun écrirait les postmortems “à sa façon” (un avec severite, l’autre avec priority, un autre sans rien). Avec le schéma, tout le monde suit la même structure.
-
Ouvrir le fichier de configuration des collections
Éditez
src/content.config.tspour ajouter le schéma postmortem.Ce fichier centralise la définition de toutes les collections de contenu (docs, blog, etc.). Vous allez y ajouter les champs spécifiques aux postmortems.
src/content.config.ts import { defineCollection } from 'astro:content';import { docsSchema } from '@astrojs/starlight/schema';import { blogSchema } from 'starlight-blog/schema';import { z } from 'astro:content';// Schema pour les postmortems SREconst postmortemSchema = z.object({title: z.string(),description: z.string(),incident_date: z.string(),severity: z.enum(['critical', 'high', 'medium', 'low']),services_affected: z.array(z.string()),duration_minutes: z.number(),incident_lead: z.string(),participants: z.array(z.string()),status: z.enum(['draft', 'published', 'archived']).default('draft'),});export const collections = {docs: defineCollection({schema: docsSchema({extend: (context) => {const base = blogSchema(context);// Ajouter les champs postmortem de manière optionnellereturn base.extend({incident_date: z.string().optional(),severity: z.enum(['critical', 'high', 'medium', 'low']).optional(),services_affected: z.array(z.string()).optional(),duration_minutes: z.number().optional(),incident_lead: z.string().optional(),participants: z.array(z.string()).optional(),status: z.enum(['draft', 'published', 'archived']).optional(),});}})}),};Explication ligne par ligne :
- Lignes 7-17 : Définition du schéma postmortem (pour référence, mais pas directement utilisé)
- Lignes 25-32 : Extension du schéma
docsexistant avec les champs postmortem en optionnel (.optional()) - Pourquoi optionnel ? : Les fichiers dans
docs/ne sont pas tous des postmortems. Un guide normal n’a pas besoin deincident_date. Seuls les fichiers dansdocs/postmortems/rempliront ces champs.
Détail des champs :
Champ Type Pourquoi Exemple incident_datestring (format ISO) Date de l’incident pour tri chronologique "2025-05-15"severityenum (4 valeurs) Criticité strictement définie (évite les variations) critical,high,medium,lowservices_affectedarray de strings Liste des services impactés (permet de filtrer) ["api-client", "frontend"]duration_minutesnumber Durée pour calculer le MTTR (Mean Time To Recovery) 125(= 2h05)incident_leadstring Responsable de la gestion de l’incident "Marie Dubois"participantsarray de strings Personnes impliquées dans la résolution ["Marie", "Thomas", "Sophie"]statusenum Workflow de publication (draft → published → archived) draft,published,archived -
Créer le dossier des postmortems
Pourquoi un dossier dédié ? : Tous les fichiers dans
src/content/docs/postmortems/seront automatiquement reconnus comme des postmortems par Astro. C’est le principe de la “convention over configuration” : la structure du répertoire définit le type de contenu.Fenêtre de terminal mkdir -p src/content/docs/postmortems -
Vérifier que le schéma fonctionne
Créez un fichier de test pour valider :
Pourquoi tester ? : Avant de créer le vrai template, vérifiez que le schéma fonctionne. Si vous avez fait une erreur de syntaxe dans
config.ts, le build vous le dira maintenant au lieu de plus tard.Fenêtre de terminal cat > src/content/docs/postmortems/test.md << 'EOF'---title: "Test postmortem"description: "Validation du schéma"incident_date: "2025-01-13"severity: highservices_affected:- test-serviceduration_minutes: 30incident_lead: Test Userparticipants:- Test Userstatus: draft---## TestCeci est un test de validation du schéma.EOFLancez le build pour vérifier :
Fenêtre de terminal npm run buildRésultat attendu :
17:07:53 [content] Synced content17:07:54 [build] ✓ Completed in 500ms.Si vous voyez cette sortie sans erreur, le schéma fonctionne correctement.
Si vous voyez une erreur, c’est généralement :
- Une faute de frappe dans
severity(ex:critiqueau lieu decritical) - Un champ manquant (ex: oubli de
duration_minutes) - Une erreur dans
config.ts(parenthèses, virgules)
Vous pouvez supprimer le fichier de test une fois validé :
Fenêtre de terminal rm src/content/docs/postmortems/test.md - Une faute de frappe dans
Créer le script de génération
Section intitulée « Créer le script de génération »Pourquoi un script plutôt que copier-coller ?
Section intitulée « Pourquoi un script plutôt que copier-coller ? »Imaginez créer un nouveau postmortem à chaque incident :
- Sans script : Copier un ancien postmortem, remplacer tous les champs un par un, risquer d’oublier quelque chose, formater le YAML manuellement → 5-10 minutes
- Avec script : Répondre à 8 questions, le fichier est généré automatiquement avec tous les champs correctement formatés → 1 minute
Le script garantit aussi que :
- Le nom de fichier suit le format
YYYY-MM-DD-slug.md(tri chronologique) - Le YAML est toujours valide (pas d’erreur d’indentation)
- Toutes les sections obligatoires sont présentes
-
Créer le dossier scripts
Fenêtre de terminal mkdir -p scripts -
Créer le script de génération
Voir le code complet du script (157 lignes)
scripts/create-postmortem.js #!/usr/bin/env nodeimport { writeFileSync, existsSync } from 'fs';import { createInterface } from 'readline';const rl = createInterface({input: process.stdin,output: process.stdout});function question(query) {return new Promise(resolve => rl.question(query, resolve));}function slugify(text) {return text.toLowerCase().normalize('NFD').replace(/[\u0300-\u036f]/g, '').replace(/[^a-z0-9]+/g, '-').replace(/^-+|-+$/g, '');}async function main() {console.log('\n📝 Création d\'un nouveau postmortem SRE\n');const title = await question('Titre de l\'incident : ');const description = await question('Description courte : ');const incidentDate = await question('Date de l\'incident (YYYY-MM-DD) : ');const severity = await question('Sévérité (critical/high/medium/low) : ');const services = await question('Services affectés (séparés par des virgules) : ');const duration = await question('Durée en minutes : ');const lead = await question('Responsable incident : ');const participants = await question('Participants (séparés par des virgules) : ');const servicesArray = services.split(',').map(s => s.trim());const participantsArray = participants.split(',').map(s => s.trim());const slug = slugify(title);const filename = `src/content/docs/postmortems/${incidentDate}-${slug}.md`;if (existsSync(filename)) {console.error(`\n❌ Le fichier ${filename} existe déjà !`);rl.close();process.exit(1);}const template = `---title: "${title}"description: "${description}"incident_date: "${incidentDate}"severity: ${severity}services_affected:${servicesArray.map(s => ` - ${s}`).join('\n')}duration_minutes: ${duration}incident_lead: ${lead}participants:${participantsArray.map(p => ` - ${p}`).join('\n')}status: draft---## Résumé[Décrivez brièvement l'incident en 2-3 phrases : quoi, quand, impact]## Chronologie### Détection- **Date/Heure** : ${incidentDate}- **Comment** : [Comment l'incident a-t-il été détecté ?]- **Par qui** : ${lead}### Investigation- **HH:MM** - [Action entreprise]- **HH:MM** - [Découverte importante]- **HH:MM** - [Autre événement]### Résolution- **HH:MM** - [Action de résolution]- **HH:MM** - [Vérification du retour à la normale]## Impact### Services touchés${servicesArray.map(s => `- **${s}** : [Décrire l'impact]`).join('\n')}### Métriques- **Durée** : ${duration} minutes- **Utilisateurs impactés** : [Nombre ou pourcentage]- **Requêtes en échec** : [Si applicable]- **Perte financière estimée** : [Si applicable]## Cause racine### Cause immédiate[Qu'est-ce qui a directement causé l'incident ?]### Causes contributives1. [Facteur qui a facilité ou aggravé l'incident]2. [Autre facteur]### Pourquoi cela s'est-il produit ?Utilisez la méthode des "5 Pourquoi" :1. **Pourquoi** l'incident s'est-il produit ? → [Réponse]2. **Pourquoi** [réponse précédente] ? → [Réponse]3. **Pourquoi** [réponse précédente] ? → [Réponse]4. **Pourquoi** [réponse précédente] ? → [Réponse]5. **Pourquoi** [réponse précédente] ? → [Cause racine]## Ce qui a bien fonctionné- [Point positif #1]- [Point positif #2]## Ce qui peut être amélioré- [Point d'amélioration #1]- [Point d'amélioration #2]## Actions correctives| Action | Responsable | Date limite | Statut | Priorité ||--------|-------------|-------------|--------|----------|| [Action #1] | [@personne] | YYYY-MM-DD | ⏳ En attente | Haute || [Action #2] | [@personne] | YYYY-MM-DD | ⏳ En attente | Moyenne || [Action #3] | [@personne] | YYYY-MM-DD | ⏳ En attente | Basse |### Statuts possibles- ⏳ En attente- 🚧 En cours- ✅ Terminé- ❌ Annulé## Leçons apprises### Ce que nous avons appris1. [Leçon #1]2. [Leçon #2]### Ce que nous ferons différemment1. [Changement #1]2. [Changement #2]## Références- [Lien vers le ticket d'incident]- [Lien vers les métriques]- [Lien vers les logs]`;writeFileSync(filename, template);console.log(`\n✅ Postmortem créé : ${filename}`);console.log('\n💡 Prochaines étapes :');console.log(' 1. Remplissez les sections du postmortem');console.log(' 2. Changez le statut de "draft" à "published" quand terminé');console.log(' 3. Lancez "npm run build" pour générer le site\n');rl.close();}main().catch(error => {console.error('Erreur:', error);rl.close();process.exit(1);}); -
Rendre le script exécutable
Fenêtre de terminal chmod +x scripts/create-postmortem.js -
Tester le script
Lancez le script :
Fenêtre de terminal node scripts/create-postmortem.jsSortie interactive :
📝 Création d'un nouveau postmortem SRETitre de l'incident : Panne base de données PostgreSQL productionDescription courte : Indisponibilité complète du service client pendant 2h suite à un problème de réplicationDate de l'incident (YYYY-MM-DD) : 2025-05-15Sévérité (critical/high/medium/low) : criticalServices affectés (séparés par des virgules) : api-client,frontend,dashboardDurée en minutes : 125Responsable incident : Marie DuboisParticipants (séparés par des virgules) : Marie Dubois,Thomas Martin,Sophie Laurent✅ Postmortem créé : src/content/docs/postmortems/2025-05-15-panne-base-de-donnees-postgresql-production.md💡 Prochaines étapes :1. Remplissez les sections du postmortem2. Changez le statut de "draft" à "published" quand terminé3. Lancez "npm run build" pour générer le site
Exemple de postmortem complet
Section intitulée « Exemple de postmortem complet »Voici un exemple réaliste de postmortem SRE structuré :
Voir le postmortem complet : Panne PostgreSQL production
---title: "Panne base de données PostgreSQL production"description: "Indisponibilité complète du service client pendant 2h suite à un problème de réplication"incident_date: "2025-05-15"severity: criticalservices_affected: - api-client - frontend - dashboardduration_minutes: 125incident_lead: Marie Duboisparticipants: - Marie Dubois - Thomas Martin - Sophie Laurentstatus: published---
## Résumé
Le 15 mai 2025 à 14h23, une défaillance de la réplication PostgreSQL a provoqué une indisponibilité complète de l'API client et des interfaces frontend. L'incident a duré 2h05 minutes et a impacté 100% des utilisateurs. La résolution a nécessité une bascule manuelle sur le serveur secondaire après identification d'un blocage de réplication causé par une transaction longue.
## Chronologie
### Détection
- **Date/Heure** : 2025-05-15 à 14:23- **Comment** : Alertes Prometheus - Erreurs 500 sur l'API client (taux > 50%)- **Par qui** : Marie Dubois (ingénieure SRE de permanence)
### Investigation
- **14:23** - Alerte Prometheus déclenchée : API client retourne 500- **14:25** - Vérification des logs applicatifs : timeout de connexion PostgreSQL- **14:28** - Connexion au serveur PostgreSQL primaire : réplication en retard de 15 minutes- **14:32** - Identification d'une transaction bloquée depuis 14:15 (requête analytics longue)- **14:35** - Tentative de kill de la transaction bloquée : échec- **14:38** - Décision de bascule sur le serveur secondaire- **14:42** - Promotion du secondaire en primaire- **14:45** - Mise à jour de la configuration HAProxy- **14:48** - Redémarrage des pods API client
### Résolution
- **14:52** - API client opérationnelle sur nouveau primaire- **15:05** - Vérification complète : toutes les métriques normales- **15:28** - Reconstruction du serveur défaillant comme nouveau secondaire
## Impact
### Services touchés
- **api-client** : Indisponibilité totale (100% des requêtes en erreur)- **frontend** : Pages utilisateur inaccessibles (erreurs de chargement)- **dashboard** : Console d'administration en erreur
### Métriques
- **Durée** : 125 minutes (2h05)- **Utilisateurs impactés** : 12 453 utilisateurs actifs (100%)- **Requêtes en échec** : 47 892 requêtes HTTP 500- **Perte financière estimée** : ~15 000 € (estimation basée sur la perte de transactions)- **SLA respecté** : Non (SLA mensuel : 99.9% → 99.85% ce mois-ci)
## Cause racine
### Cause immédiate
Une requête analytics non optimisée exécutée sur le serveur primaire à 14:15 a verrouillé des tables critiques pendant plus de 20 minutes. Ce verrouillage a bloqué le processus de réplication WAL (Write-Ahead Logging), créant un retard de réplication croissant jusqu'à rendre le secondaire inutilisable comme failover.
### Causes contributives
1. **Absence de timeout sur les requêtes analytics** : La requête problématique ne disposait d'aucune limite de temps d'exécution2. **Monitoring insuffisant du lag de réplication** : Le seuil d'alerte était fixé à 30 minutes (trop élevé)3. **Requête analytics exécutée directement sur le primaire** : Pas de séparation entre charge opérationnelle et analytique
### Pourquoi cela s'est-il produit ?
Utilisez la méthode des "5 Pourquoi" :
1. **Pourquoi** l'incident s'est-il produit ? → Le serveur PostgreSQL primaire ne répondait plus2. **Pourquoi** le serveur primaire ne répondait plus ? → La réplication était bloquée par une transaction longue3. **Pourquoi** la transaction bloquait la réplication ? → Elle verrouillait des tables critiques sans timeout4. **Pourquoi** n'y avait-il pas de timeout ? → Les requêtes analytics n'étaient pas isolées et non limitées5. **Pourquoi** les requêtes analytics n'étaient pas isolées ? → **Cause racine : Absence d'architecture séparant les charges OLTP et OLAP**
## Ce qui a bien fonctionné
- **Détection rapide** : Les alertes Prometheus ont fonctionné correctement (< 2 minutes)- **Communication** : Le statut a été communiqué sur status.example.com en moins de 10 minutes- **Procédure de failover** : Bien que manuelle, la procédure était documentée et a été suivie efficacement- **Collaboration d'équipe** : Les 3 ingénieurs SRE ont coordonné l'incident sans confusion
## Ce qui peut être amélioré
- **Automatisation du failover** : La bascule manuelle a pris 20 minutes- **Monitoring de la réplication** : Alertes trop tardives (seuil à 30 min)- **Séparation des charges** : Aucun read-replica dédié pour l'analytics- **Documentation** : La procédure de rollback n'était pas documentée
## Actions correctives
| Action | Responsable | Date limite | Statut | Priorité ||--------|-------------|-------------|--------|----------|| Implémenter Patroni pour failover automatique | @thomas-martin | 2025-06-01 | 🚧 En cours | Haute || Configurer un read-replica dédié analytics | @sophie-laurent | 2025-05-25 | ✅ Terminé | Haute || Abaisser le seuil d'alerte réplication à 5 minutes | @marie-dubois | 2025-05-16 | ✅ Terminé | Haute || Ajouter statement_timeout sur toutes les connexions | @thomas-martin | 2025-05-20 | ✅ Terminé | Haute || Documenter la procédure de rollback | @marie-dubois | 2025-05-18 | ✅ Terminé | Moyenne || Créer des game days pour tester le failover | @sophie-laurent | 2025-06-15 | ⏳ En attente | Moyenne || Auditer toutes les requêtes analytics | @thomas-martin | 2025-05-30 | 🚧 En cours | Basse |
### Statuts possibles
- ⏳ En attente- 🚧 En cours- ✅ Terminé- ❌ Annulé
## Leçons apprises
### Ce que nous avons appris
1. **Importance de l'isolation des charges** : Mélanger OLTP et OLAP sur le même serveur est dangereux2. **Failover automatique essentiel** : 20 minutes de bascule manuelle représentent 16% du temps total d'incident3. **Monitoring proactif** : Des alertes à 30 minutes de lag arrivent trop tard pour prévenir un incident4. **Timeouts obligatoires** : Toute requête doit avoir une limite de temps, sans exception
### Ce que nous ferons différemment
1. **Architecture** : Toutes les nouvelles bases de données auront un read-replica dédié pour l'analytics2. **Automation** : Patroni sera le standard pour toute base PostgreSQL critique3. **Testing** : Un game day trimestriel simulera des pannes de base de données4. **Governance** : Toute connexion applicative aura un statement_timeout configuré
## Références
- [Ticket incident INC-2025-0515](https://jira.example.com/INC-2025-0515)- [Dashboard Grafana - PostgreSQL](https://grafana.example.com/d/postgresql-overview)- [Logs Loki - Période incident](https://loki.example.com/logs?from=1715780000&to=1715787600)- [Status page communication](https://status.example.com/incidents/2025-05-15-database)Build et vérification
Section intitulée « Build et vérification »Après avoir créé vos postmortems, lancez le build :
npm run buildRésultat du build :
17:07:53 [content] Synced content17:07:54 [build] ✓ Completed in 500ms.17:07:55 [vite] ✓ built in 1.15s generating static routes17:07:55 ✓ Completed in 162ms. Indexed 6 pagesVérifiez que les pages sont générées :
ls -la dist/postmortems/Sortie :
drwxrwxr-x 3 bob bob 4096 janv. 13 17:07 .drwxrwxr-x 8 bob bob 4096 janv. 13 17:07 ..drwxrwxr-x 2 bob bob 4096 janv. 13 17:07 2025-05-15-panne-postgresqlChaque postmortem génère un répertoire avec une page HTML statique :
ls -lh dist/postmortems/2025-05-15-panne-postgresql/Sortie :
-rw-rw-r-- 1 bob bob 63K janv. 13 17:07 index.htmlConfigurer la sidebar
Section intitulée « Configurer la sidebar »Pour rendre les postmortems accessibles dans la navigation, ajoutez-les à la sidebar d’Astro.
-
Ouvrir la configuration Astro
Éditez
astro.config.mjs:astro.config.mjs export default defineConfig({site: 'https://example.com',integrations: [starlight({title: 'My Docs',sidebar: [{label: 'Guides',items: [{ label: 'Example Guide', slug: 'guides/example' },],},{label: 'Reference',autogenerate: { directory: 'reference' },},// Ajouter la section SRE{label: 'SRE',collapsed: false,items: [{ label: 'Postmortems', autogenerate: { directory: 'postmortems' } },{ label: 'Métriques & SLO', slug: 'sre/metriques-slo' },{ label: 'Observabilité', slug: 'sre/observabilite' },{ label: 'Runbooks', slug: 'sre/runbooks' },],},],}),],});Explication :
autogenerate: { directory: 'postmortems' }: Génère automatiquement un lien pour chaque fichier danssrc/content/docs/postmortemscollapsed: false: La section SRE est ouverte par défaut- Les autres liens (
metriques-slo, etc.) pointent vers des pages normales (sans collection)
-
Vérifier dans le navigateur
Lancez le serveur de développement :
Fenêtre de terminal npm run devOuvrez http://localhost:4321/ et vérifiez que la sidebar affiche :
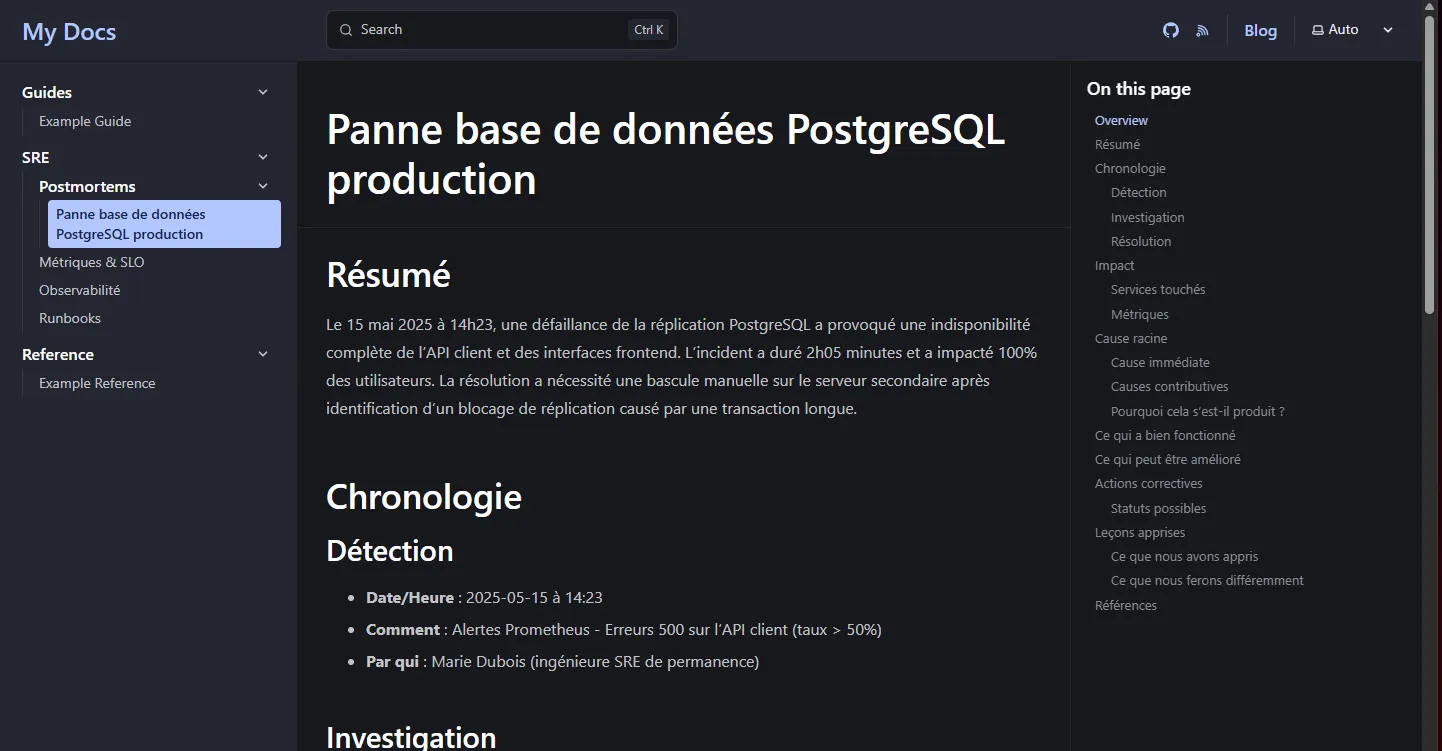
Résultat du build avec sidebar
Section intitulée « Résultat du build avec sidebar »Après avoir configuré la sidebar, le build génère toutes les pages :
17:14:52 [build] 18 page(s) built in 2.68s Indexed 9 pagesPages générées :
find dist -name "index.html" | grep -E "(sre|postmortem)"Sortie :
dist/sre/runbooks/index.htmldist/sre/observabilite/index.htmldist/sre/metriques-slo/index.htmldist/postmortems/2025-05-15-panne-postgresql/index.htmlÀ retenir
Section intitulée « À retenir »- Les postmortems SRE transforment les incidents en opportunités d’apprentissage
- Un schéma Zod valide les métadonnées et structure la documentation
- La méthode des 5 Pourquoi remonte à la cause racine système
- Un script de génération accélère la création de nouveaux postmortems
- La culture blameless analyse les systèmes, pas les personnes
- Les actions correctives avec responsables et dates limitent la récurrence
Prochaines étapes
Section intitulée « Prochaines étapes »Vous pouvez aller plus loin :
- Personnaliser le style : Adaptez le template du site Astro pour refléter votre charte graphique (logo, couleurs, typographie).
- Automatiser le workflow : Intégrez le script dans votre CI/CD pour créer automatiquement un postmortem draft dès qu’un incident est déclaré.
- Ajouter des graphiques : Utilisez Chart.js ou D3.js pour visualiser les métriques (MTTR, répartition par sévérité, évolution temporelle).
- Créer des vues filtrées : Générez des pages par sévérité, par service ou par trimestre pour analyser les tendances.
- Intégrer avec PagerDuty : Récupérez automatiquement les données d’incident (date, durée, participants) depuis votre outil de gestion d’incidents.